试验分流模型介绍
|
收藏
1. 为什么要进行试验流量分流
当我们的产品发展到了一定的体量之后,业务模块会变得更多,组织架构也变得更复杂。在这个精细化优化运营的阶段,我们需要大量且广泛的进行试验,因此需要试验平台能够实现更精细化的试验流量管理,能够帮助我们精准调配、灵活调整平台用户流量,精打细算地实现流量的充分利用,同时还要保证试验结果的科学合理。
本篇文档将为大家介绍神策的分流模型和分流规则,方便大家理解进行流量分配操作之后可能产生的影响,如使用过程中遇到难以解释的分流现象,也可通过本篇文章辅助进行排查归因。
2. 试验流量分流中的基本概念
本节为大家介绍流量分流过程中的几个基本概念或关系:流量分配、流量互斥、流量过滤、流量正交、流量释放
如果您当前还未了解试验层的概念,可查阅:试验层
2.1. 流量分配

假设单一试验层内是100%的用户流量,神策A/B测试可实现将100%的流量按照自定义比例分配给多个实验,并可知晓在当前层中还剩余多少流量可供分配。在创建试验时,可进一步设置多个试验组,并规定各试验组可获得的流量比例。
2.2. 流量互斥

完成试验流量和试验组流量的分配之后,神策A/B测试会保证「同层内不同试验之间」及「同试验不同组之间」的流量互斥。即:
- 同层内进入了「试验A」的用户,就不再可以进入「试验B」,以此类推
- 同试验内进入「对照组」的用户,就不再可以进入「试验组1」,以此类推
以确保用户只能参与其中一个试验或试验组别,进而实现试验效果的独立计算。
2.3. 流量过滤

部分场景下,我们会针对某些特定人群进行试验,因此神策A/B测试会在流量分配进入试验之后,进行筛选条件的过滤,进一步将符合条件的用户划分到不同试验组中实施试验。在此过程中,我们会先为试验分配流量,再进行流量过滤,并将不符合条件的用户合理丢弃,以确保丢弃的流量不会影响到流量池剩余流量的用户属性比例。
如上图案例所示:
假设本试验层为试验A分配了40%的流量,经过条件筛选后,其舍弃了其中50%的不符合条件的人群(占总体流量的20%),这部分不符合试验A筛选条件流量(红色用户)并不会释放回本层剩余流量中,否则会造成本层内其他试验中红绿用户的比例和用户总体相比存在偏移,红色用户占比变多,进而影响其他试验的观测结果。
2.4. 流量正交

当流量不够用时,最好的办法是在同一个用户身上做更多的试验,因此我们可以给每个用户叠加试验层。但由于试验和试验间存在互相影响的可能性,因此神策A/B测试在底层实现了将流量均匀打散的算法,最大程度的保证不同层试验之间的影响是均匀的,这种状态我们称为流量正交。
如上图案例所示:
在流量不正交的情况下,「广告位试验」试验组提升10%的用户没有均匀流向「活动页试验」,导致「活动页试验」中试验组最终产生的效果,大概率来自「广告位试验」,因此造成了试验观测的干扰。而在流量正交的情况下,「广告位试验」试验组提升10%的用户,均匀的分散在「活动页试验」的对照组和试验组中,这样尽管两试验存在互相影响,在流量正交后影响被相互抵消了,使得「活动页试验」或其他试验也可以独立进行分析,得到准确的试验结果。
2.5. 流量释放
当一个试验已经结束或已经发布(发布同样意味着试验结束)时,本试验层被该试验占据的流量比例将会被释放出来,可被本层中其他试验使用,以达到循环使用试验层的目的。若试验处于暂停状态,则该试验本身不会再进入新用户,但试验占据的流量比例并不会被释放(已被其占据的用户分桶仍然不能为其他试验所用)
3. 试验分流模型架构
在《Overlapping Experiment Infrastructure: More, Better, Faster Experimentation》中,Google给出了一套业界通用的分层分流试验框架。神策A/B测试以此为蓝版,结合多种业务场景及客户诉求,从不同维度推演出如下的试验模型,详细描述了流量分层和分流的解决方案。
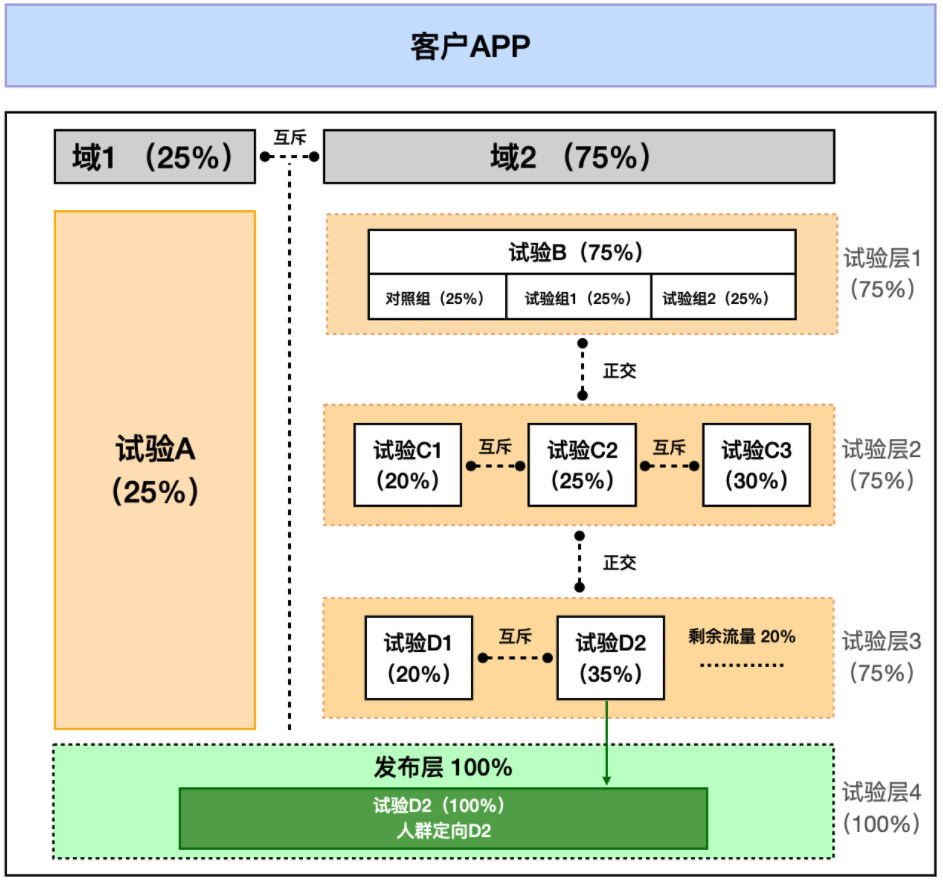
本节我们来解释下模型中的基本单元和关系:试验、试验层、发布层、试验域。
3.1. 试验域
“试验域”是指整体流量的分区,域之间是互斥的,如我们的模型示例,以某种分流方式将整体流量分为了1、2两个域,此时:
- 域1(25%)+ 域2(75%)= 100% 的流量
不同的域之间的流量不会重叠。划分域的目的,是为了进行完全隔离的分区,进行互不干扰的试验。如架构图所示:
- 试验域内可以嵌套多个试验层,试验层1、2、3嵌套在域2中,共享用域2中75%的流量。
- 发布层不受试验域的影响, 发布计划默认会发布到所有域。
3.2. 试验层
“试验层”是试验的集合,主要作用为保证试验间的流量隔绝,确保试验的效果可追溯到某单一变量上,如架构图所示:
- 试验层2中的C1、C2、C3三个试验间流量互斥,且流量相加等于试验层总流量75%。
- 试验层3中D1、D2两个试验占用试验层3中55%的流量,剩余的20%流量可为其他试验所用。
- 层与层之间的关系是正交的,即彼此互不影响,相互独立,可以同时进行实验而不互相干扰。
3.3. 发布层
“发布层”是一种特殊的试验层,其不受试验域、试验层影响,当某试验在本层已经完成试验过程,将会被放入一个单独的发布层中,面向所用户发布。如架构图所示:
- 试验D2完成了试验验证后,会进入发布层,独占一个发布层,改称为“发布计划D2”
- 此时「发布计划D2」不再受到域2的影响,其发布范围可能会覆盖「域1」的用户,原有的域间互斥关系失效
- 此时「发布计划D2」不再受到试验层3的影响,其发布范围可能会覆盖「试验D1」的用户,原有的层内互斥关系失效
- 此时「发布计划D2」仍然会继承「试验D2」对试验用户人群的定义,发布面向对象仍需符合原试验D2的筛选条件
3.4. 试验
“试验”指从线上流量中抽取一小部分,完全随机地分配各个版本,通常原版本即为对照组,其余版本视为各试验组,在符合统计学检验的前提下,对比哪个试验组版本相对于对照组更优。试验由若干试验组组成,且各组间流量互斥,流量之和为该试验被分配到的总流量。
- 参考示例:试验B被分配了75%的流量,对照组、试验组1、2分别被分配25%的流量且三组之间流量互斥,流量之和为该试验B总流量。
4. 流量规划最佳实践
4.1. 试验层规划和管理
4.1.1. 规范试验层命名
通常建议试验层的命名方式为“ xx业务部门_xx业务模块试验层 “,如:
- 算法团队_猜你喜欢推荐算法试验层
- 产品团队_充值模块试验层
- 运营团队_裂变活动试验层
最终实现各部门工作场景的分割,同时以业务模块划分来保障层和层之间足够区隔,避免试验间的互相影响。(虽然有正交可以抵消试验间影响,但指标绝对值仍然是受到多个试验影响的,只不过影响均等而已,如果我们期望的更准确地知晓实际的业务指标数值水平,应尽量做好试验层区分)
4.1.2. 保持清爽的试验层和试验环境
当前的试验层是可重复被利用的,如果层内试验下线,则会释放出流量,我们可以借此特性保持尽可能少的试验层数量,适时删除不用的试验层,避免试验层的冗余,它将会有以下好处:
- 创建试验时,容易找到归属层
- 更清楚的知晓会互相影响的试验都在哪些地方
4.1.3. 创建一些临时层给不好定归属的试验
工作中我们经常会碰见部分试验是较特殊的试验,并不需要归属于某些常用试验层,因此可以把它丢入临时试验层中,以独占流量和共享流量的方式运行,进而减少为这些试验单独创建的冗余试验层。
4.2. 单个试验流量的精准预估
如果我们能够精准地预估单个试验所会占用的流量,就可以更加精准的计算该分配给其多少流量,可通过神策A/B测试提供的「样本量预估工具」,结合神策分析系统提供的「事件分析」工具,进行单个试验的流量预估。若您想了解详细的试验样本预估方法,请查阅:试验样本预估指南
注:本文档内容为神策产品使用和技术细节说明文档,不包含适销类条款;具体企业采购产品和技术服务内容,以商业采购合同为准。
