切换试验分流主体
|
收藏
功能说明
该功能是高级功能,默认不开启。
神策 A/B 测试默认支持神策 ID和登录ID 作为分流主体,如需开启其他分流主体,请联系您的客户成功经理申请开通。
分流主体是什么?
分流主体是试验中进行分流的随机化单元。在试验时需确保分流主体与评价指标分析主体相同。
用户主体( 一般为 user_id )是主流的随机化单元。如果分流主体是用户维度,那指标分析的主体也应该是用户,例如人均会话数、人均点击量、人均支付金额等。
当然在实际业务场景中,可能使用其他分流主体。设备主体(一般为device_id)也是一种常用的随机化单元,按照设备进行随机化意味着每台设备产生的指标数据是独立的,即使同一用户登录了不同的设备,也不会将该用户在不同设备产生的数据进行关联。比如一些工具类产品,本身没有注册体系,不涉及用户登录前后一致性体验问题,则适合使用设备主体进行分流。又比如在点餐机或者自动售卖机(一般为Android系统)的试验场景中,不需要用户进行登录即可进行下单购买,那么此时试验的分流主体和分析主体就应为这个独立设备,可以用每台设备的平均下单时长(完成下单的总时长/独立设备数)作为评价指标,用来衡量下单页优化效果。
除了以上两种常用的试验主体外,也可能会存在其他主体,例如在推荐算法试验中,可以用推荐的页面(或推荐的商品)作为试验主体单位,这种试验的变化是用户不易察觉到的,那么相应的可以用页面的人均访问时长(推荐页面总访问时长/推荐页面数量)作为评价指标分析主体。
在评估选择使用哪种分流主体时,需要结合具体试验场景来考虑。可以重点从用户体验一致性、分流主体和评价指标主体一致性上这两角度综合评估。通常用户主体能够更好的保持用户登在录前后体验的一致性,设备主体则忽略用户的登录状态,使同设备上切换账号也能保持想相同的策略,两种方案各有侧重,接下来将详细说明不同主体的适用场景及其优劣势。
神策A/B测试支持的分流主体
神策A/B测试支持按照神策ID、设备ID、登录ID和自定义ID进行分流,满足不同业务场景的测试需求。
神策 ID
神策 A/B 测试已完全支持 IDM1.0 和 2.0,暂未完全支持 IDM 3.0,如您的产品选择 IDM 3.0 的协议标识用户,请联系您的技术顾问经理进一步了解情况。
神策A/B测试提供的试验单位默认与神策分析系统进行埋点统计的用户标识保持一致,即使用神策生成的神策 ID 来标识用户,神策 ID 将关联用户的登录 ID 及匿名 ID,并将用户在登录前后的行为进行打通(除非您的产品选择的是只用设备 ID 的方案,具体用户标识可查看 标识用户 IDM1.0、IDM2.0、标识用户 IDM3.0 )。
神策 ID 的优势
在实际业务场景中,绝大部分用户只有一台设备,并对应一个应用账号。通过用户关联能够保证绝大多数用户在登录前后,获取到一致的试验结果。
除了以上能够保持用户登录前后分流结果一致性和准确的用户追踪外,使用用户主体分流还具备以下优势:
- 神策 ID 一般为登录账号、手机号等,这类 ID 更具稳定性,适合更长周期观察用户行为数据
- 试验主体与分析主体的一致性,能够确保与神策分析平台能力打通(神策分析默认使用神策 ID)
- 能够使用神策用户属性和用户分群能力,更好的支持定向试验的受众圈选
神策ID的局限性
当然在实际业务中,也会存在一些特殊情况,比如:
- 一个用户可能有多台设备,并在多个设备上登录同一个账号
- 或者一个用户有多个账号,在同一台设备上进行切换登录的场景
由于切换设备和频繁登录场景的特殊性,分流结果可能无法保证登录或者切换设备前后保持一致。下面举例说明:
| 用户 | 行为 | 结果 |
|---|---|---|
| A | 启动一台新设备 [X] | 获取到分流结果为 [a] |
| A | 在设备 [X] 登录账号 [123] | 登录账号 [123] 和设备 [X] 发生关联,登录后分流结果仍为 [a] |
| A | 启动另一台新设备 [Y] | 由于未登录前,无法获取该设备的关联关系,因此会当做新用户分流,分流结果可能 [b] |
| A | 在设备 [Y] 上登录账号 [123] | 登录后会重新获取分流,由于会按照登录账号 [123] 获取分流,分流结果为 [a] |
| B | 在设备 [X] 登录账号 [456] | 登录前设备分流结果为 [a],由于登录了新账号 [456],该用户会被重新分流,分流结果可能为 [c] |
如果用户在多设备下有频繁登录行为,那么可能会导致:
用户在后续新设备登录前后的分流结果不一致,对用户体验有一定影响
- 由于登录前后分流结果可能不一致,该用户数据的统计会一定的偏差
因此,在用户主体分流下,不适用于以下业务场景:
- 在实际业务中,如果有一定比例用户有多设备频繁登录,且不希望用户在不同设备上登录前后试验策略不一致
- 有一定比例用户有个账号在同一设备上频繁切换登录,且不希望在不同账号切换时,展示的试验策略不一致
针对以上局限性,可以结合具体业务场景,考虑使用设备ID进行分流,下面进行详细介绍。
设备ID
若当前接入神策的用户标识仅使用了设备 ID ,则此时神策 ID 即为设备 ID ,神策A/B测试的分流主体就为设备主体。
在客户端应用中,支持通过使用设备ID进行分流。神策 A/B 测试使用匿名 ID(anonymous_id)来标识设备。区别于按照神策 ID分流,神策使用在使用设备ID分流时,分流服务直接按照请求参数中的 anonymous_id 进行分流。
{
"anonymous_id":"xxx",
"platform":"ios",
"abtest_lib_version":["0.0.1"],
"login_id":"", // 非必选
"custom_ids": { "custom_id1": "xx1", "custom_id2": "xx2"}, // 非必选,自定义主体ID
"properties":{}, // 非必选
"custom_properties": { // 客户自定义属性
"string":"string", // 字符串类型
},
"param_name": "test_experiment" // 当前客户获取的试验参数
"origin_platform":"H5", // H5 打通携带数据
}需要注意的是,为了能够保证分流和统计主体一致,在使用设备ID分流时,需要将 anonymous_id 作为公共属性上报到事件上。
设备ID的优势
设备ID一个最大的特点是能够保证在同一设备上的策略一致性,不会因为用户切换账号而看到不一样的功能体验;一般也适用于没有注册体系的业务场景,比如工具类产品。
设备ID的局限性
设备ID的局限性也比较明显,首先是不具备跨设备或跨平台的一致性。如果业务侧或合规要求对用户在不同设备登录时的策略一致性要求较高且比较敏感,则不适用于使用设备ID分流。
下面举例说明:
| 用户 | 行为 | 结果 |
|---|---|---|
| A | 启动一台新设备 [X] | 获取到分流结果为 [a] |
| A | 在设备 [X] 登录账号 [123] | 同一设备,登录后分流结果仍为 [a] |
| A | 在设备 [Y] 登录账号 [123] | 由于设备不同,因此会当做新用户分流,分流结果可能 [b] |
另外,如果在接入神策时 标识用户 的神策 ID 并非直接采用设备ID,而只是在神策A/B测试中使用设备主体分流,则无法适配以下神策平台能力:
- 试验指标不支持按照用户维度的属性进行筛选
- 受众筛选仅支持随机流量,不支持按照用户用户分群和用户标签筛选受众
- 随机流量仅支持预置属性和自定义属性筛选,不支持用户属性筛选
- 设备主体试验暂不支持生成试验标签
实施注意事项
- 使用前,需确保已在神策将 anonymous_id 已设置为公共属性
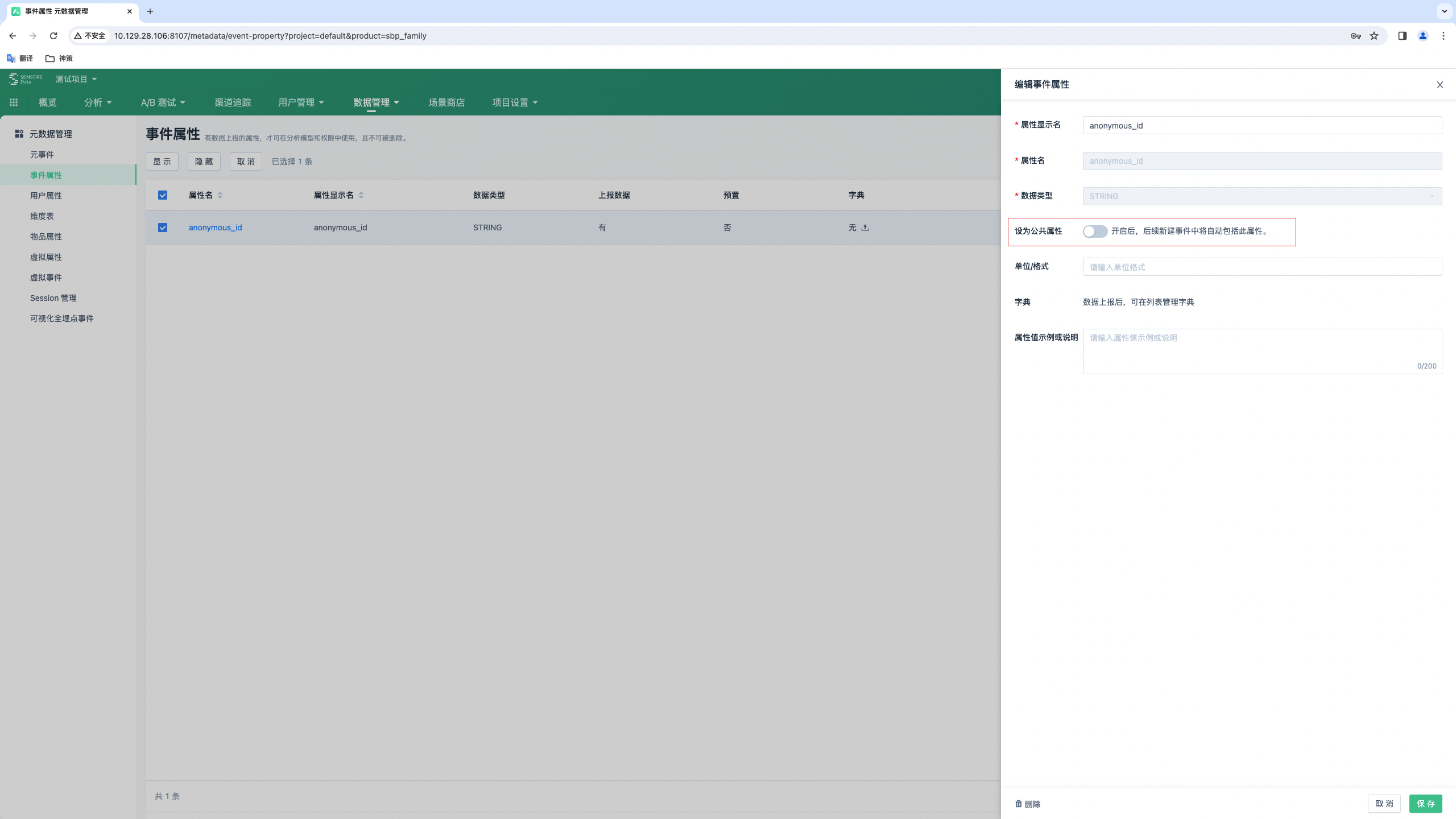
- 在 SDK 上报数据时,需要将 anonymous_id 作为公共属性上报
- 在录入设备 ID 调试设备时,需要通过控制台获取 anonymous_id,暂不支持扫码录入(扫码目前默认录入神策 ID )
登录ID
登录ID指loginId,通常为业务ID,只对登录状态的用户进行分流(当一个应用新用户),一般较多应用于服务端试验。
登录ID的优势
登录ID广泛应用于服务端试验,一个最大的特点是能够避免因 IDMapping延迟造成用户策略跳变,影响用户体验。
登录ID的局限性
同设备ID一样,登录ID分流也有比较明显的局限性,用户在登录前无法参与分流,因此不适用于某些客户端应用中存在用户账号登录的场景。
另外,由于在接入神策时 使用神策 ID进行 标识用户 ,当使用登录ID进行分流时,则暂时不支持适配以下神策平台能力:
- 试验指标不支持按照用户维度的属性进行筛选
- 受众筛选仅支持随机流量,不支持按照用户用户分群和用户标签筛选受众
- 随机流量仅支持预置属性和自定义属性筛选,不支持用户属性筛选
- 登录ID分流试验暂不支持生成试验标签
自定义主体
前置条件
- 应用版本需升级到 V0.6.1+
- A/B SDK版本:Android SDK v0.2.1+、iOS SDK v0.2.1+、Java SDK v0.0.4+、Golang SDK v0.0.2+、Python SDK v0.0.1+
- 确保将接口中定义的自定义主体 ID 参数已上报为事件的公共属性
在实际业务中,除了支持使用神策用户主体和设备主体分流以为,支持使用客户自定义的主体 ID 进行分流。
例如,上面提到的推荐算法试验中,可以用推荐的商品作为试验主体单位。此时用户不再被随机分组,所有的用户会同时收到算法A和算法B的推荐结果(对应不同的商品 ID),却不知道内容是由算法A还是算法B推荐的。通过计算不同推荐算法的的商品平均点击率(商品点击次数/商品曝光次数)。
自定义主体的优势
自定义主体具备更强的扩展性,能够实现用户主体以外的其他任何其他主体分流。例如使用手机号、会员 ID等其他用户标识;或者进行商品推荐、内容推荐等以物品的角度分流并衡量试验指标。
自定义主体的局限性
由于自定义主体 ID (custom_ids)依赖于手动传入,因此有一定的开发成本。
另外由于自定义主体 ID 非神策用户体系,因此无法完美适配以下神策平台能力:
- 试验指标不支持按照用户维度的属性进行筛选
- 暂时不支持留存指标(v0.8.0及以上版本支持留存指标)
- 受众筛选仅支持随机流量,不支持按照用户用户分群和用户标签筛选受众
- 随机流量仅支持预置属性和自定义属性筛选,不支持用户属性筛选
- 设备主体试验暂不支持生成试验标签
实施注意事项
自定义主体参数校验规则
参数名:
- 仅支持英文、数字、下划线,且不能以数字和 $ 开头;长度不超过100。
- 不能使用神策保留字段。详情请查阅 神策保留字段。
参数值:
- 类型为String,长度大于0且不超过102
异常情况处理:
- 当定义的参数名不合法时,在编译时 SDK 直接报错;
- 若使用自定义主体请求的参数值不合法时,此次按照未命中试验处理。
注意事项
- 根据业务需求,定义自定义主体 ID 参数(例如 会员账号、手机号等,参数名支持自定义),并将其手动添加到接口请求参数 custom_ids 字典中。并确保在请求分流服务时,所有用户都携带自定义主体 ID
- 将自定义主体 ID 提供给神策后台分流服务,由神策技术支持人员将其配置到分流服务后台
- 在录入自定义主体试验的调试设备时,需要通过控制台获取 custom_ids,暂不支持扫码录入(扫码目前默认录入神策 ID )
{
"anonymous_id":"xxx",
"platform":"ios",
"abtest_lib_version":["0.0.1"],
"login_id":"", // 非必选
"custom_ids": { "custom_id1": "xx1", "custom_id2": "xx2"}, // 非必选,自定义主体ID
"properties":{}, // 非必选
"custom_properties": { // 客户自定义属性
"string":"string", // 字符串类型
},
"param_name": "test_experiment" // 当前客户获取的试验参数
"origin_platform":"H5", // H5 打通携带数据
}如何使用试验分流主体?
规划试验层

神策 A/B 测试支持在一个项目内使用不同主体进行试验,意味在着一个用户请求时,可能同时命中不同分流主体的试验。
为了保证流量的高效、合理利用,对于不同分流主体试验,应当分属于不同主体类型的试验层。在创建试验层时,需要明确当前试验层的主体类型,并确保后续层内试验都使用对应主体进行试验。
试验配置页选择分流主体
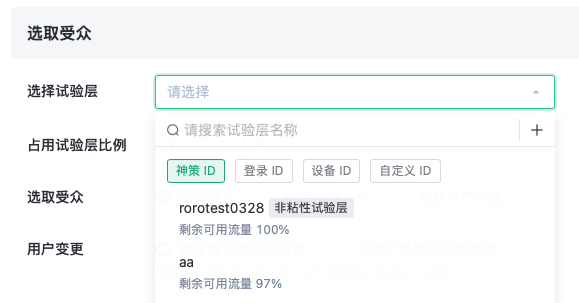
试验配置页选择对应主体的试验层,当选择非神策ID主体时,则受众、指标中将不可选择用户属性相关内容。
注:本文档内容为神策产品使用和技术细节说明文档,不包含适销类条款;具体企业采购产品和技术服务内容,以商业采购合同为准。
