自定义查询
|
收藏
本文档所描述的内容属于神策分析的高级使用功能,涉及较多技术细节,适用于对相关功能有经验的用户参考。如果对文档内容有疑惑,请咨询神策值班同学获取一对一的协助。
对于使用现有的 UI 功能暂时无法满足的高级数据需求,我们提供了更加自由的自定义查询功能。该功能支持使用标准 SQL 来对神策分析的所有数据进行查询,同时也包含对查询结果的简单可视化。
注: 当前版本的自定义查询工具基于 HUE 项目构建。
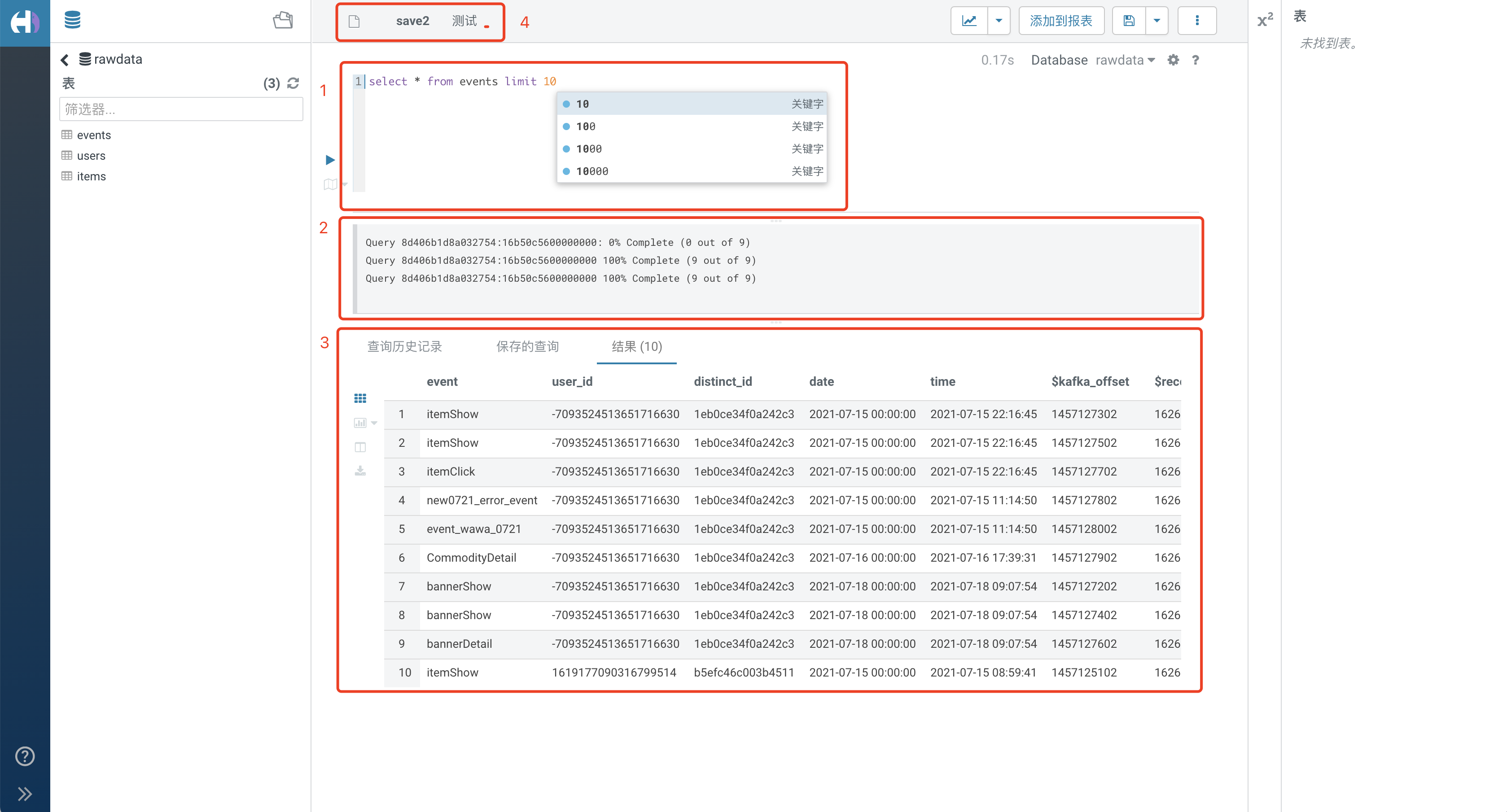
1. 基本功能
1.1. SQL查询
在编辑框中输入要查询的 SQL,支持SQL关键字联想和格式化。
注: 自定义查询中使用 select * 语句能查询到隐藏的预置属性,不能查询到隐藏的自定义属性。
1.2. 查看查询进度
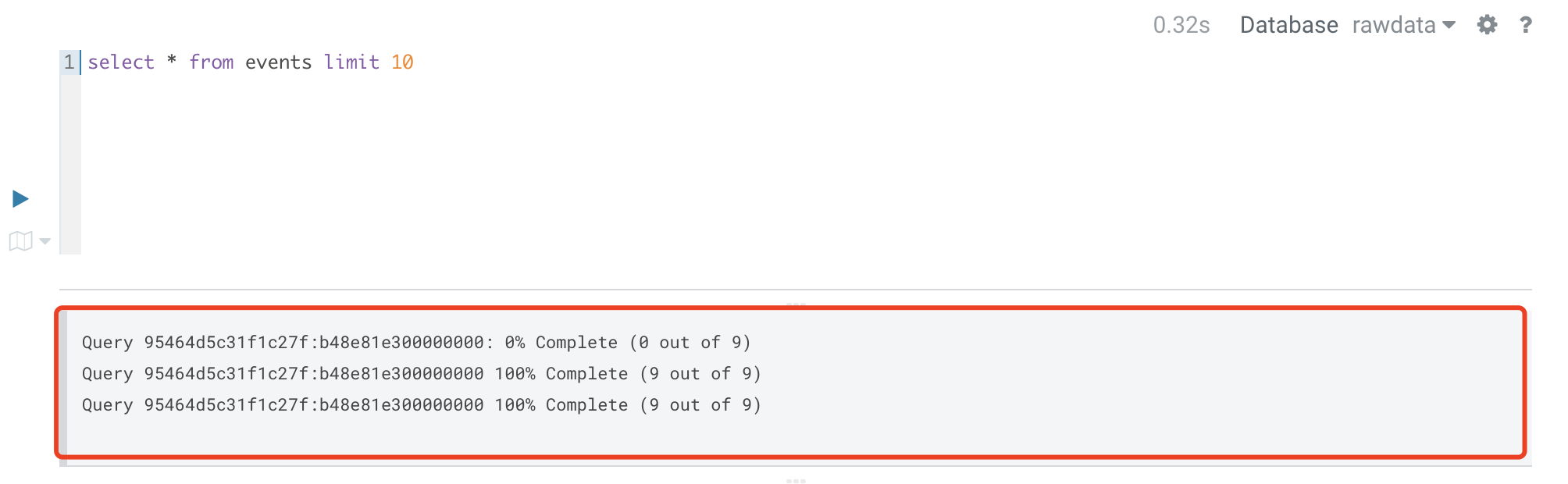
支持查看SQL查询进度。
1.3. 查询结果
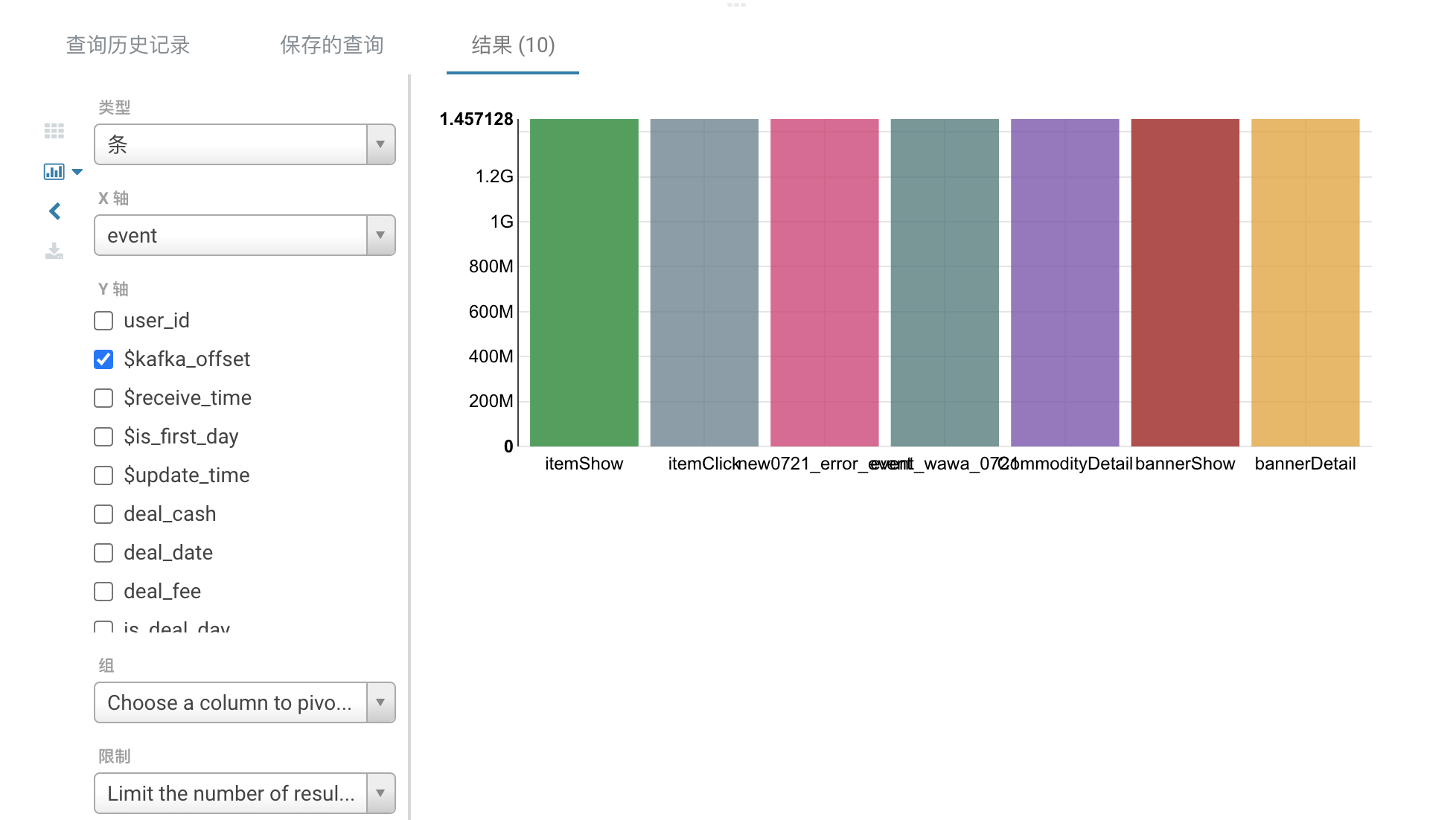
1、支持通过使用查询结果中的可视化图表工具,进行数据分析。
2、查询结果支持下载Excel和Csv文件。出于性能的考虑,前端展示的结果最大只有 1k 条,而 CSV 下载的结果最大是 100w 条,如果需要下载更多数据请使用查询 API。
1.4. 保存SQL
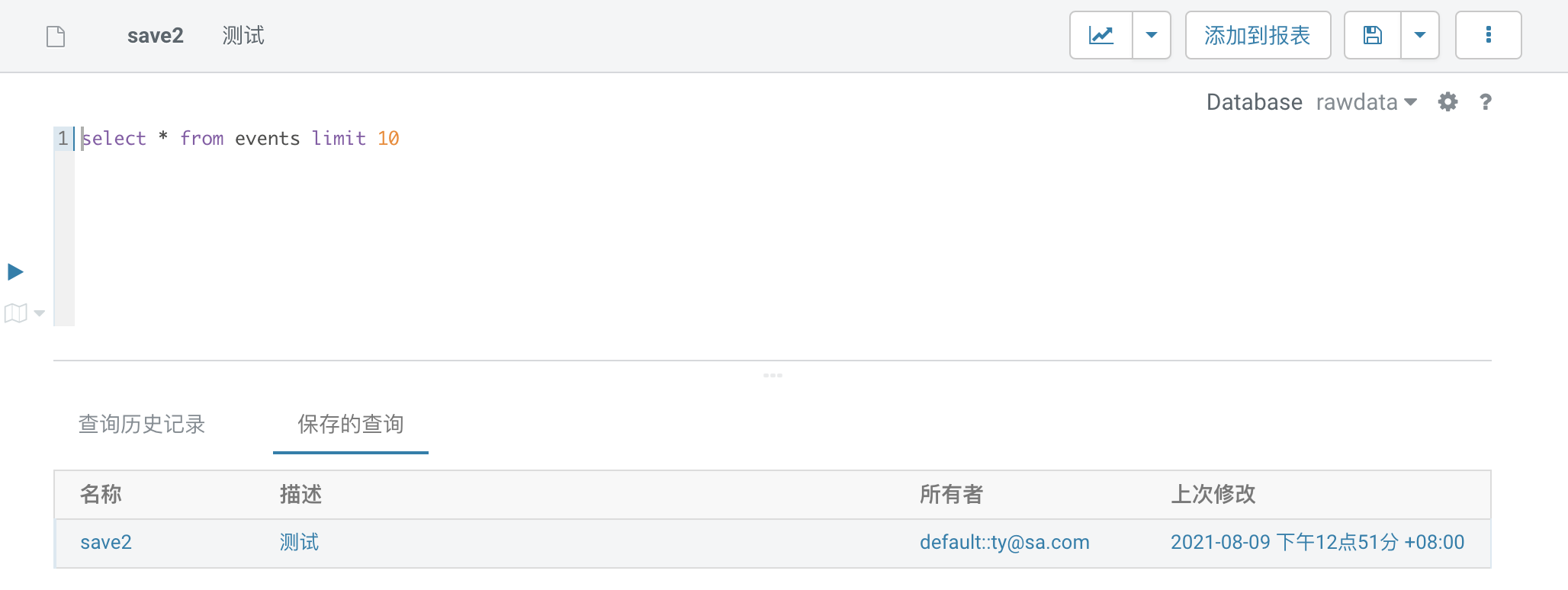
1、支持对当前查询的SQL进行保存,SQL名称支持自定义,并支持添加备注信息。
2、可双击保存的查询列表中的SQL语句,进行SQL语句查看和运行。
1.5. 查看历史记录
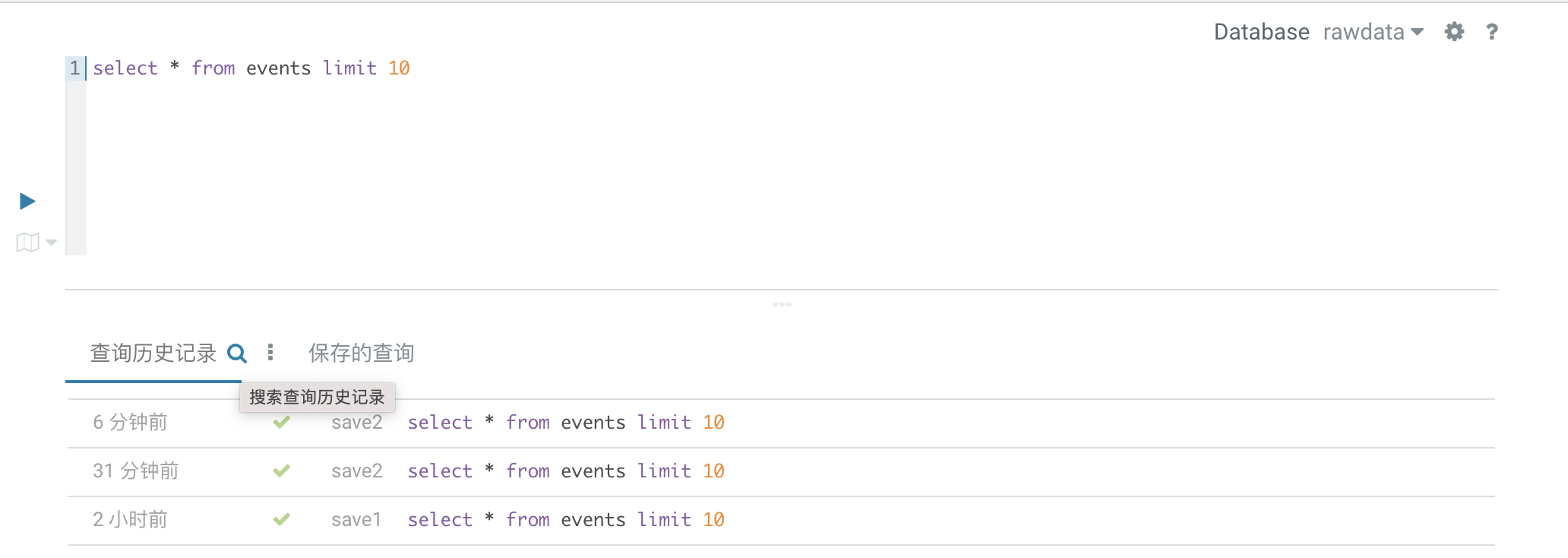
支持查看历史SQL查询记录,并支持对历史记录进行搜索。
2. 高级功能
2.1. 添加到报表
支持对当前SQL查询结果,快速保存到报表。
2.2. 中间表
本功能为高级功能,默认不开启,请联系运维开启功能。
在一些业务场景中,实际的数据结果都需要经过复杂计算才能在结果表上展现出来;除此之外还有一些数据量较大的表,在其上进行统计查询通常会效率很低;为了解决查询逻辑复杂、数据量大导致的性能问题,神策上线了中间表的功能。
2.2.1. 使用说明
一、支持新建查询创建中间表,支持已保存的查询或者已保存的中间表另存为中间表
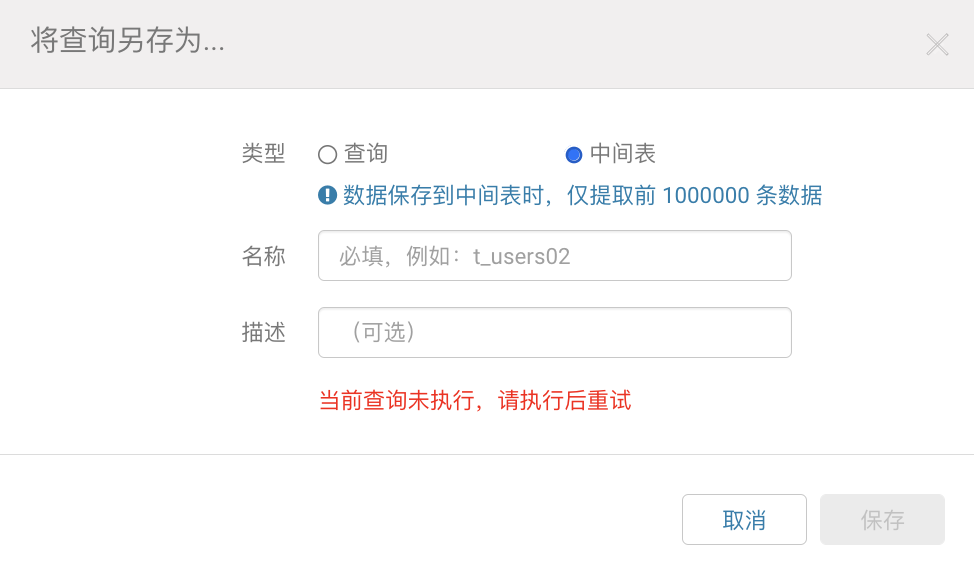
二、出于查询效率的考虑,自定义查询功能在中间表有一些使用上的限制,具体说明如下:
- 不支持用户分群表 / 标签表在「跨项目」查询时,创建中间表。
预览模式不支持保存中间表
查询结果 ≥ 1 条时候可以保存为中间表;若查询超过 100万 条的数据,保存到中间表时只获取前 100万 条的数据保存(默认是100万,数据量可联系客户成功配置)
一个账号在一个项目下最多支持保存10个表,中间表仅创建人可见、编辑、删除
中间表仅当做临时表使用,不支持自动刷新,需要用户在使用时在hue中使用需要手动刷新数据
2.2.2. 使用示例
如何使用session表创建指标:需要在查询语句中加入/*SESSION_TABLE_DATE_RANGE=[2018-01-01,2018-01-05]*/
/*event表和session表创建中间表示例*/ SELECT sessions_session.event, sessions_session.user_id, sessions_session.distinct_id, sessions_session.`date`, EVENTS.showEntrance, EVENTS.action_type FROM EVENTS JOIN sessions_session ON sessions_session.user_id = events.user_id/*SESSION_TABLE_DATE_RANGE=[2018-01-01,2018-01-05]*/ where events.`date` between '2022-03-21' and '2022-03-27'SQL
2.3. 跨项目查询
本功能为高级功能,默认不开启,请联系运维开启功能。
2.3.1. 场景举例
如在 游戏行业 中,客户将找茬游戏的数据存在项目一中,拼图游戏的数据存在项目二中,策略抽卡游戏的数据存在项目三中,其中找茬和拼图游戏主要是为策略游戏导流。那么跨项目查询可以满足以下场景的需求:
场景一大盘数据查看:管理层在一个报表中查看三种类型游戏的日活、留存、充值等汇总数据,实现步骤如下:
- 联系客户成功开始跨项目查询功能
- 了解自己需要的项目英文名、项目 ID,以及项目内表结构
- 在自定义分析中写查询语句,执行查询并将查询结果保存到报表数据源
- 在报表中选择新建报表,选择对应的数据源配置报表看板
场景二数据洞察 :对项目一 / 项目二中转化为项目三用户情况进行分析等,实现步骤如下:
- 联系客户成功开始跨项目查询功能
- 了解自己需要的项目名称,以及项目内表结构
- 在自定义分析中写查询语句,执行查询,下载分析结果到本地或制作成报表
2.3.2. 使用说明
很抱歉如今跨项目查询仍处于试用阶段, 获取项目表内结构的过程有些繁琐
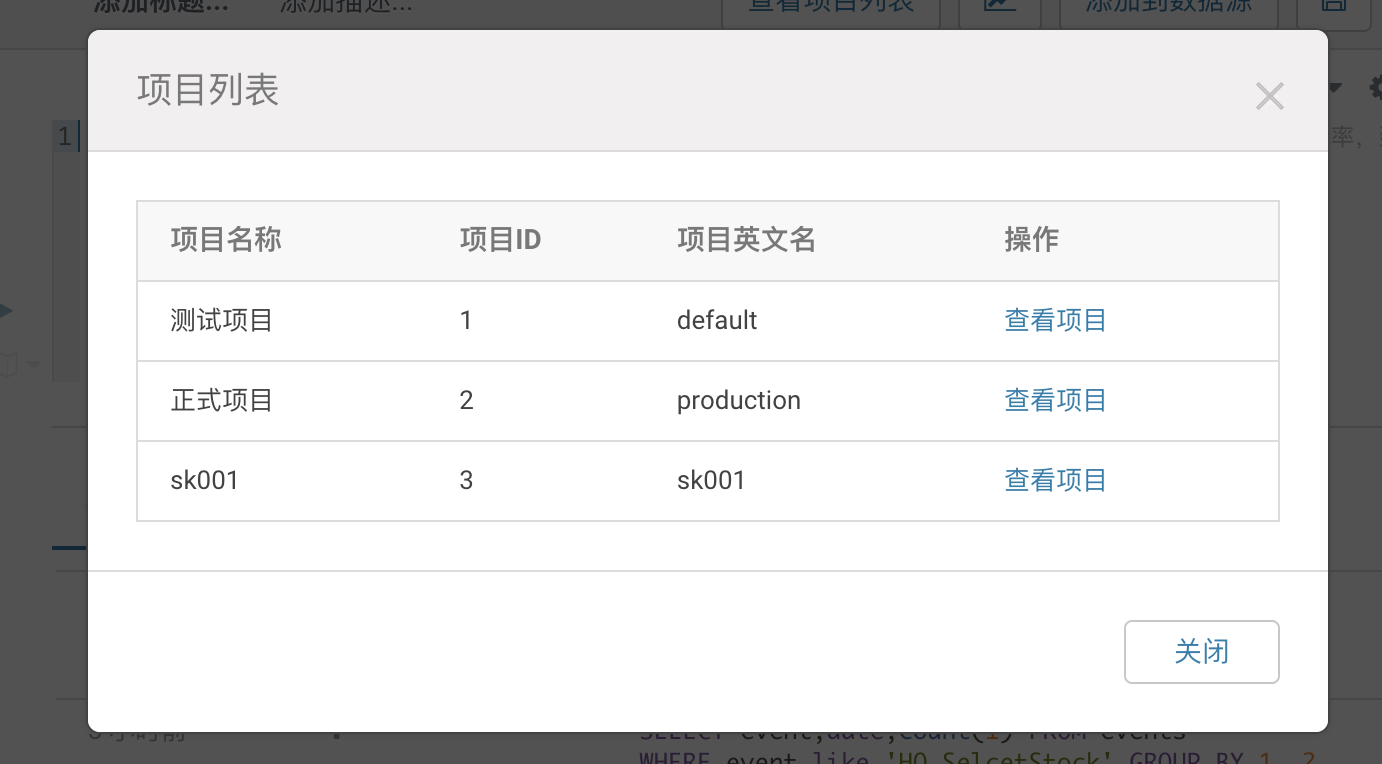
一、如何获得自己有权限的项目英文名以及项目 ID:点击页面右上角「查看项目列表」弹出项目列表弹窗。支持查看用户自己有权限的项目名称、项目ID、项目英文名、以及操作,点击操作列的查看项目可打开对应项目页面

二、如何了解各个项目内的表结构:目前仅支持切换到具体项目之后进入自定义查询页面查看
三、什么情况下需要指定数据表所属项目:书写一个可进行跨项目查询数据的 SQL 语句,就需要指定所查询的神策的数据表的所属项目
rawdata下的events users items表、分群、标签、session表可用固定前缀「horizon」+ 「_${projectName}_${projectId}」来修饰数据表进行置顶所属项目,以项目名为 「production」项目 ID 为 「2」的项目举例(这里的项目前缀修饰起到了一个限制 db 的作用):
- horizon_production_2.events
- horizon_production_2.users
- horizon_production_2.items
- ...
其他数据表、报表、中间表他们都有自己的db,直接db.表名
- governor_production.order_detail
- blitzreport_db.daily_operation_report
- hue_medium_table_production.mothers_day_activities
- ...
2.3.3. 使用示例:以下是具体跨项目查询使用示例:
- 利用 UNION/UNION ALL 对两个项目的查询结果进行交并集处理展示
- 例如:查看两个项目 12 月以来每天进行 App安装 事件的次数
SELECT 'production' as project, date, count(1)
FROM horizon_production_2.events
WHERE event like 'AppInstall' and `date` > '2022-12-01'
GROUP BY 1,2
UNION ALL
SELECT 'default' as project, date, count(1)
FROM horizon_default_1.events
WHERE event = 'AppInstall' and `date` > '2022-12-01'
GROUP BY 1,2- 利用 JOIN 语句对两个项目的数据表进行联合查询
- 例如:查看当日下在「projectId=1, projectName=default」的项目下的「user_group_user_group_1」的用户分群在 「projectId=2, projectName=production」的项目中进行的 「AppClick」的总次数
SELECT count(1)
FROM horizon_production_2.events events
INNER JOIN horizon_default_1.user_group_user_group_1 user_group1 ON events.user_id = user_group1.user_id
WHERE event = 'AppClick' and `date` = CURRENT_DATE()- 例如:查看在「projectId=2, projectName=production」的项目下的「event」在 「projectId=1, projectName=zwp_001_3.」的项目中 「date、distinct_id、`$element_target_url`、`$country`、`$utm_campaign`」的数据情况
SELECT e1.event,
e2.date,
e2.distinct_id,
e2.`$element_target_url`,
e2.`$country`,
e2.`$utm_campaign`
FROM horizon_production_2.events e1
LEFT JOIN horizon_zwp_001_3.events e2 ON e1.event = e2.event2.4. 脱敏
本功能为高级功能,默认不开启,请联系运维开启功能。
根据登录用户在SBP数据权限、脱敏属性配置页面,对需要进行事件属性或者用户属性需要脱敏字段的配置,在hue界面书写的sql语句中,对脱敏字段进行预校验。
【现阶段对于脱敏显示、禁止分组与筛选 不做区分,SQL中涉及到了脱敏属性直接报错】

目前实现的 SQL 解析效果:
- 支持 SELECT 语句,包含:Select、From、Where、Group By、Order By
- 支持在 FROM 和 WHERE 后带有子查询 (与 Impala 一致)
- 暂不支持 WHERE 后的子查询中又嵌套子查询,例如:where column=(select xxx from (...) t where...)
- 暂不支持 FROM 后带有多个同层级的子查询,例如:from (...) a, (...) b
- 支持FROM 后带有多个表,或一个子查询
3. 日期过滤
date 字段表示事件发生时的日期,精确到天,可以用于快速过滤数据。需要特别注意,任何时候都应当尽量使用 date 字段进行过滤,而不是 time 字段。
由于 date 字段的特殊性,对 SQL 操作和函数的支持有一些限制,目前支持使用的函数和表达式有:
- CURRENT_DATE() 函数,返回当天,例如 2016-08-23。
- CURRENT_WEEK() 函数,返回当周的周一,例如 2016-08-22。
- CURRENT_MONTH() 函数,返回当月的一号,例如 2016-08-01。
- INTERVAL 表达式,例如
CURRENT_DATE() - INTERVAL '1' DAY表示昨天。
以下是一些具体的例子:
- 精确过滤某一天的数据
SELECT COUNT(*) FROM events WHERE date = '2016-01-01'- 查询当天的数据
SELECT COUNT(*) FROM events WHERE date = CURRENT_DATE()- 查询最近 3 天的数据
SELECT COUNT(*) FROM events WHERE date BETWEEN CURRENT_DATE() - INTERVAL '2' DAY AND CURRENT_DATE()- 查询上个自然月的数据
SELECT COUNT(*) FROM events WHERE date BETWEEN CURRENT_MONTH() - INTERVAL '1' MONTH AND CURRENT_MONTH() - INTERVAL '1' DAY由于 date 是专门为快速的数据过滤设计的特殊字段,不支持绝大多数的时间函数。因此,如果希望使用其它时间函数,请使用 time 字段代替,例如:
SELECT datediff(now(), trunc(time, 'DD')), COUNT(*) FROM events WHERE date >= CURRENT_DATE() - INTERVAL '100' day GROUP BY 1- 按照月份聚合 2018-09-01 之后的事件数
SELECT date_sub(date,dayofmonth(date)-1) the_month,count(*) event_qty
FROM events WHERE date>'2018-09-01'
GROUP BY the_month ORDER BY the_month;- 按照星期聚合 2018-09-01 之后的事件数
SELECT date_sub(date,mod(dayofweek(date)+5,7)) the_week,count(*) event_qty
FROM events WHERE date>'2018-09-01'
GROUP BY the_week ORDER BY the_week;4. 高级选项
- 开启快速 Distinct 算法,可以大大加速类似 COUNT(DISTINCT user_id) 的计算,并且支持多个 COUNT(DISTINCT) 表达式(1.17+ 版本,不加此注释,也可以支持多个 COUNT(DISTINCT) ,但是 1.16 及之前版本,必须加此注释才能支持多个 COUNT(DISTINCT) ),缺点是会得到不完全精确的结果。例如:
SELECT COUNT(DISTINCT user_id) FROM events
WHERE date = CURRENT_DATE() /*ENABLE_APPROX_DISTINCT*/- 开启维度字典映射和维度表关联,默认关闭。例如:
SELECT $model FROM events
WHERE date = CURRENT_DATE() /*ENABLE_DIMENSION_DICT_MAPPING*/- 如果 SQL 是查询某个指定 distinct_id 的数据,可以用此选项来进行查询查询。例如:
SELECT event, time FROM events
WHERE date = CURRENT_DATE() AND distinct_id='abcdef' /*DISTINCT_ID_FILTER=abcdef*/- SQL 默认在执行 10 分钟之后会被系统强制杀死,如果希望增大超时时间可以使用如下方式:
SELECT * FROM events WHERE date = CURRENT_DATE() LIMIT 1000 /*MAX_QUERY_EXECUTION_TIME=1800*/- 对于 JOIN 类查询,可以使用 Join Hint 来指定 Join 的执行方式,可以是 SHUFFLE 或者 BROADCAST。尤其是在执行过程中如果遇到内存不足的错误,可以考虑强制指定为 SHUFFLE 模式:
SELECT COUNT(*) AS cnt FROM events
JOIN /* +SHUFFLE */ users ON events.user_id = users.id
WHERE date = CURRENT_DATE()5. 常见案例
5.1. 根据用户的 distinct_id 查询某个用户在某天的具体行为
直接使用 distinct_id 查询即可:
SELECT * FROM events WHERE distinct_id = 'wahaha' AND date = '2015-09-10' LIMIT 1005.2. 查询每天上午 10 点至 11 点的下单用户数
使用标准的 SQL 日期函数 EXTRACT 来取出小时信息。
SELECT date, COUNT(*) FROM events
WHERE EXTRACT(HOUR FROM time) IN (10, 11) AND event = 'SubmitOrder'
GROUP BY 15.3. 查询一段时间内的用户下单次数分布情况
首先计算每个用户的下单次数,然后使用 CASE..WHEN 语法来分组。
SELECT
CASE
WHEN c < 10 THEN '<10'
WHEN c < 20 THEN '<20'
WHEN c < 100 THEN '<100'
ELSE '>100'
END,
COUNT(*)
FROM (
SELECT user_id, COUNT(*) AS c FROM events
WHERE date BETWEEN '2015-09-01' AND '2015-09-20' AND event = 'SubmitOrder'
GROUP BY 1
)a
GROUP BY 15.4. 查询做了行为 A 而没有做行为 B 的用户数
使用 LEFT OUTER JOIN 计算差集。
SELECT a.user_id FROM (
SELECT DISTINCT user_id FROM events WHERE date='2015-10-1' AND event = 'BuyGold'
) a
LEFT OUTER JOIN (
SELECT DISTINCT user_id FROM events WHERE date='2015-10-1' AND event = 'SaleGold'
) b
ON a.user_id = b.user_id
WHERE b.user_id IS NULL5.5. 计算用户的使用时长
使用分析函数,根据每个用户相邻的两个事件的间隔估算累计使用时长,如果两次使用间隔超出 10 分钟则不计算。
SELECT
user_id,
SUM(
CASE WHEN
end_time - begin_time < 600
THEN
end_time - begin_time
ELSE
0
END
) FROM (
SELECT
user_id,
EXTRACT(EPOCH FROM time) AS end_time,
LAG(EXTRACT(EPOCH FROM time), 1, NULL) OVER (PARTITION BY user_id ORDER BY time asc) AS begin_time
FROM events
WHERE date='2015-5-1'
) a
GROUP BY 15.6. 获取用户的首次行为属性
使用 first_time_value(time, 其他属性) 聚合函数来获取第一次发生某行为时的相关属性
-- 示例1:获取用户第一次发生页面浏览行为时,所在的页面 URL
SELECT user_id, first_time_value(time, $url) FROM events WHERE event = '$pageview' GROUP BY user_id
-- 示例2:获取用户第一次购买时,所购买的金额
SELECT user_id, first_time_value(time, order_amount) first_order_amount FROM events WHERE event = 'payOrder' GROUP BY user_id5.7. 获取元数据管理中上传的维度字典
如果属性有维度字典话需要客户手动加一个sql注释 /*ENABLE_DIMENSION_DICT_MAPPING*/
SELECT DISTINCT orgName
FROM users /*ENABLE_DIMENSION_DICT_MAPPING*/;6. 不兼容语法变更
自定义查询引擎切换为直接查引擎模式,并将底层查询引擎版本升级到了 4.8,因此存在少量的不兼容语法变更。
- events.date 字段变为 datetime 类型, 不再作为 number 类型支持进行 number 类型的计算, 例如不支持 + - * /。例如:
/* 支持的语法 */
SELECT * FROM events WHERE date = '2021-03-01' + interval 1 day
/* 不再支持的语法 */
SELECT * FROM events WHERE date - 1 = '2021-03-01'- 使用 events.date 字段进行两表 Join 时,因为 date 字段的类型变更,根据 Join 的数据量条数,会带来不同程度的查询性能上的下降。这种写法暂时没有办法规避,我们会在后续的版本中考虑重写这个条件,避免每次计算函数。建议在性能比较敏感的场景之下,尽量从业务场景上避免 events.date 字段参与 Join 运算。例如:
/* 有性能损失的用法 */
SELECT
*
FROM
(
FROM
*
FROM
events
WHERE
date = '2021-01-02'
) a
LEFT JOIN (
SELECT
*
FROM
users
) b ON a.date = b.birthday- GROUP BY、HAVING、ORDER BY 中的别名替换逻辑与标准 SQL 行为更一致,即别名仅在顶级表达式有效,而在子表达式中无效。例如:
/* 支持的语法 */
SELECT NOT bool_col AS nb
FROM t
GROUP BY nb
HAVING nb;
/* 不再支持的语法 */
SELECT int_col / 2 AS x
FROM t
GROUP BY x
HAVING x > 3;- 新增了一系列的保留字段,这些字段是不能直接用作标识符的。如果需要将其用作标识符,则必须用反引号引起来,例如:
/* 支持的语法 */
SELECT `position` FROM events
/* 不再支持的语法 */
SELECT position FROM events- 新增的保留字段包括:
| allocate、any、api_version、are、array_agg、array_max_cardinality、asensitive、asymmetric、at、atomic、authorization、begin_frame、begin_partition、blob、block_size、both、called、cardinality、cascaded、character、clob、close_fn、collate、collect、commit、condition、connect、constraint、contains、convert、copy、corr、corresponding、covar_pop、covar_samp、cube、current_date、current_default_transform_group、current_path、current_role、current_row、current_schema、current_time、current_transform_group_for_type、cursor、cycle、deallocate、dec、decfloat、declare、define、deref、deterministic、disconnect、dynamic、each、element、empty、end-exec、end_frame、end_partition、equals、escape、every、except、exec、execute、fetch、filter、finalize_fn、foreign、frame_row、free、fusion、get、global、grouping、groups、hold、indicator、init_fn、initial、inout、insensitive、intersect、intersection、json_array、json_arrayagg、jso、n_exists、json_object、json_objectagg、json_query、json_table、json_table_primitive、json_value、large、lateral、leading、like_regex、listagg、local、localtimestamp、log10、match、match_number、match_recognize、matches、merge、merge_fn、method、modifies、multiset、national、natural、nchar、nclob、no、none、normalize、nth_value、nth_value、occurrences_regex、octet_length、of、off、omit、one、only、out、overlaps、overlay、pattern、per、percent、percentile_cont、percentile_disc、portion、position、position_regex、precedes、prepare、prepare_fn、procedure、ptf、reads、recursive、ref、references、regr_avgx、regr_avgy、regr_count、regr_intercept、regr_r2、regr_slope、regr_sxx、regr_sxy、regr_syy、release、rollback、rollup、running、savepoint、scope、scroll、search、seek、serialize_fn、similar、skip、some、specific、specifictype、sqlexception、sqlexception、sqlwarning、static、straight_join、submultiset、subset、substring_regex、succeeds、symmetric、system_time、system_user、timezone_hour、timezone_minute、trailing、translate_regex、translation、treat、trigger、trim_array、uescape、unique、unnest、update_fn、value_of、varbinary、varying、versioning、whenever、width_bucket、window、within、without |
注:本文档内容为神策产品使用和技术细节说明文档,不包含适销类条款;具体企业采购产品和技术服务内容,以商业采购合同为准。
