Custom query
|
Collect
The contents described in this document are advanced features of SaaS-based web analytics tool - Sensors Analytics and involve many technical details, which are suitable for experienced users to refer. If you have any doubts about the content of the document, please consult our staff to obtain one-to-one assistance.
For advanced data needs that cannot be met by the existing UI functions, we offer a more flexible custom query feature. This feature supports using standard SQL to query all data in the Sensorsdata platform and also includes basic visualization of query results.
Note: The current version of the custom query tool is based on HUE Project construction.
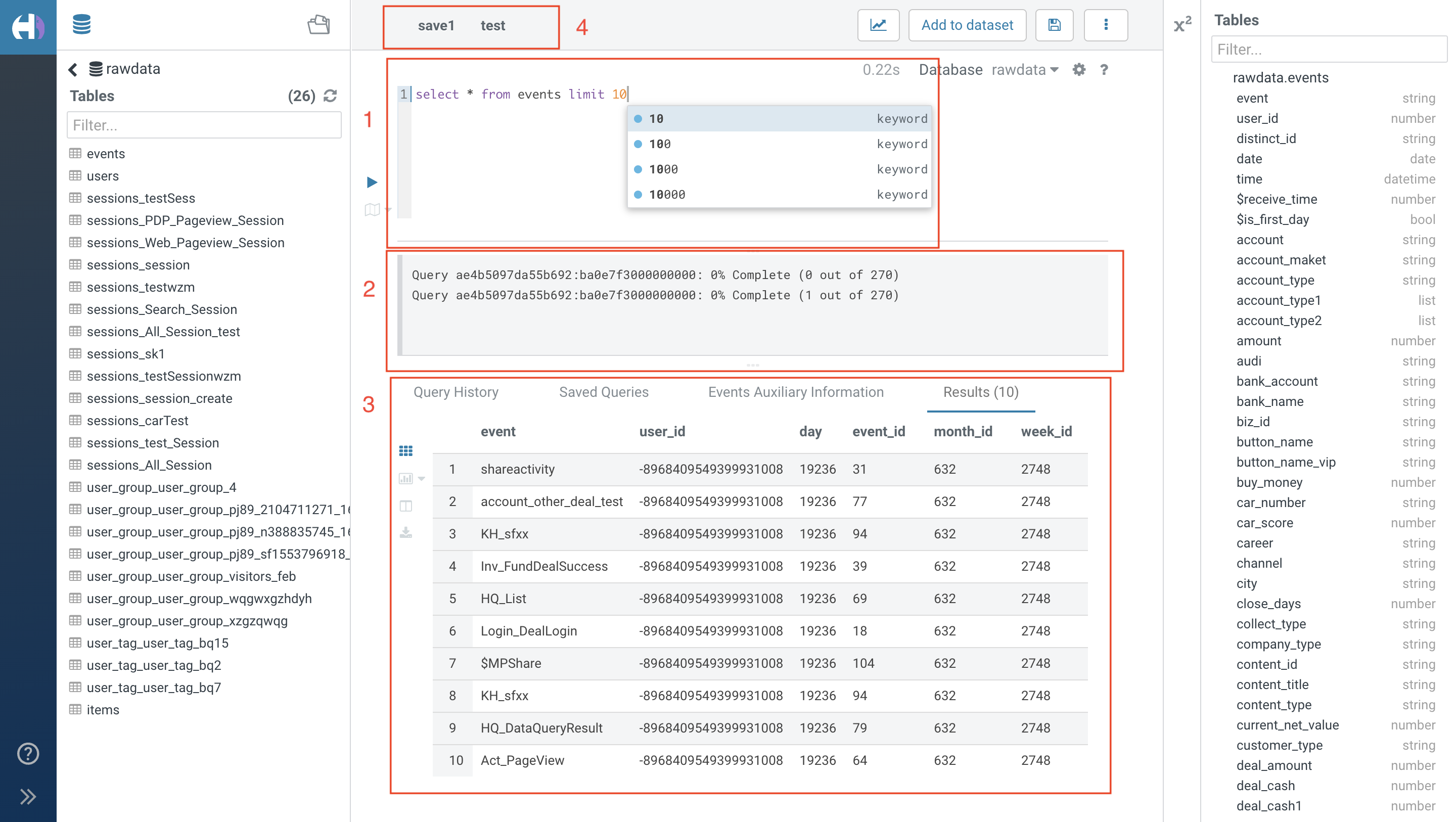
1. Basic Functionality
1.1. SQL Query
Enter the SQL query to be searched in the edit box, support SQL keyword association and formatting.
Note: Hidden preset attribute can be found using the select * statement in custom query, hidden custom attribute cannot be queried.
1.2. Viewing the query progress
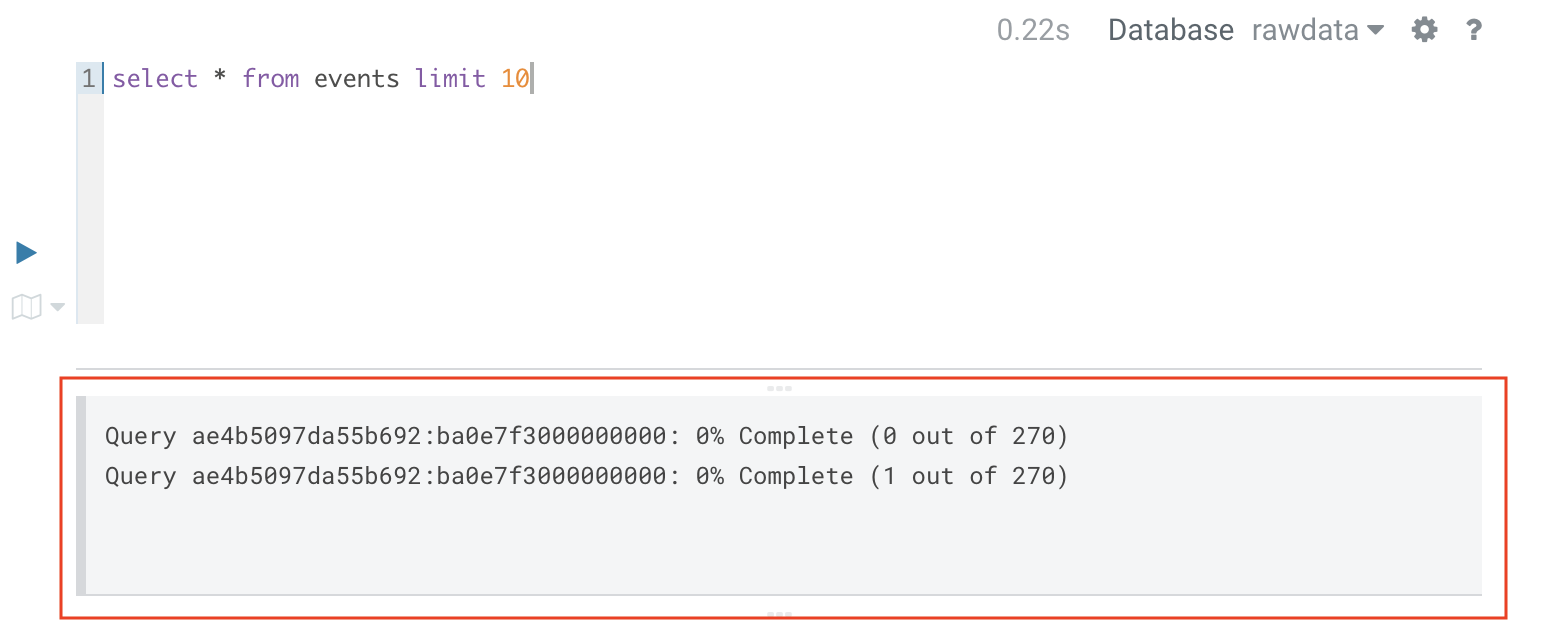
Support viewing the progress of SQL queries
1.3. Query result
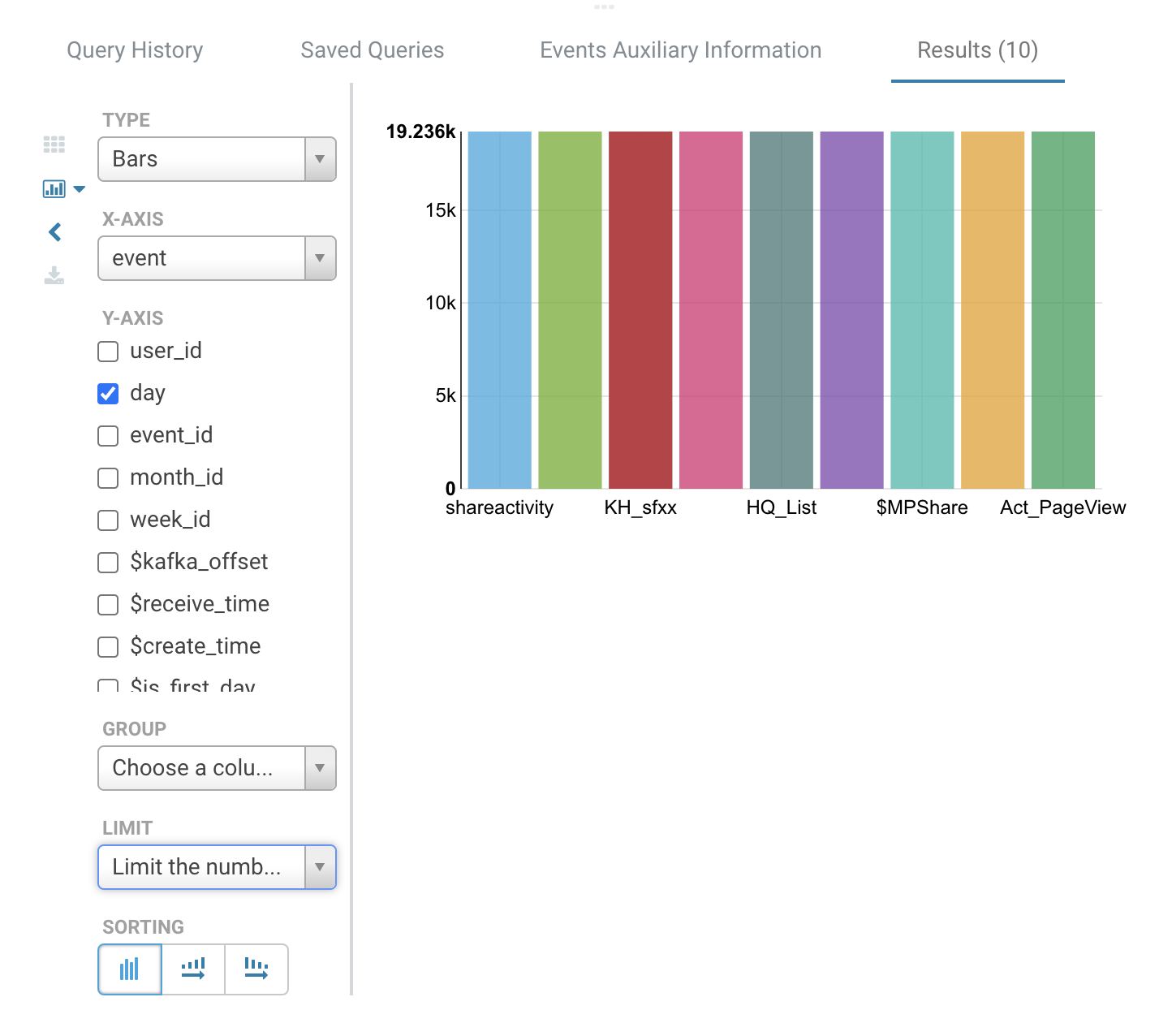
1. Support data analysis through visual chart tools in the query results.
2. Query results support downloading Excel and CSV files. For performance reasons, the maximum displayed results on the frontend is only 1k records, while the maximum results for CSV download are 10 million records. If you need to download more data, please use the query API.
1.4. Save SQL
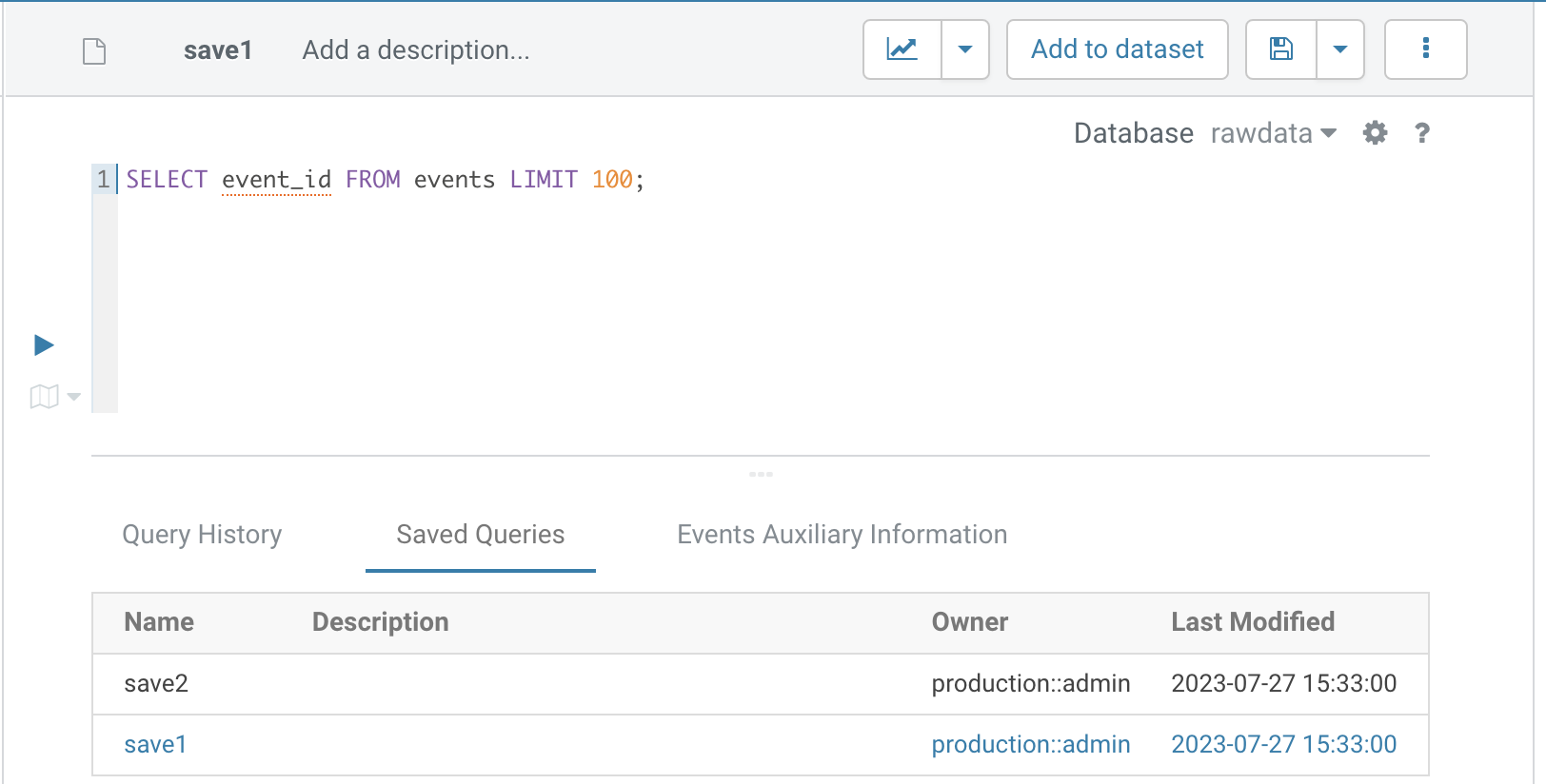
1. Support saving the current SQL query, with customizable SQL name and the ability to add comments.
2. Double-click on the saved SQL in the list to view and run the SQL statement.
1.5. View history
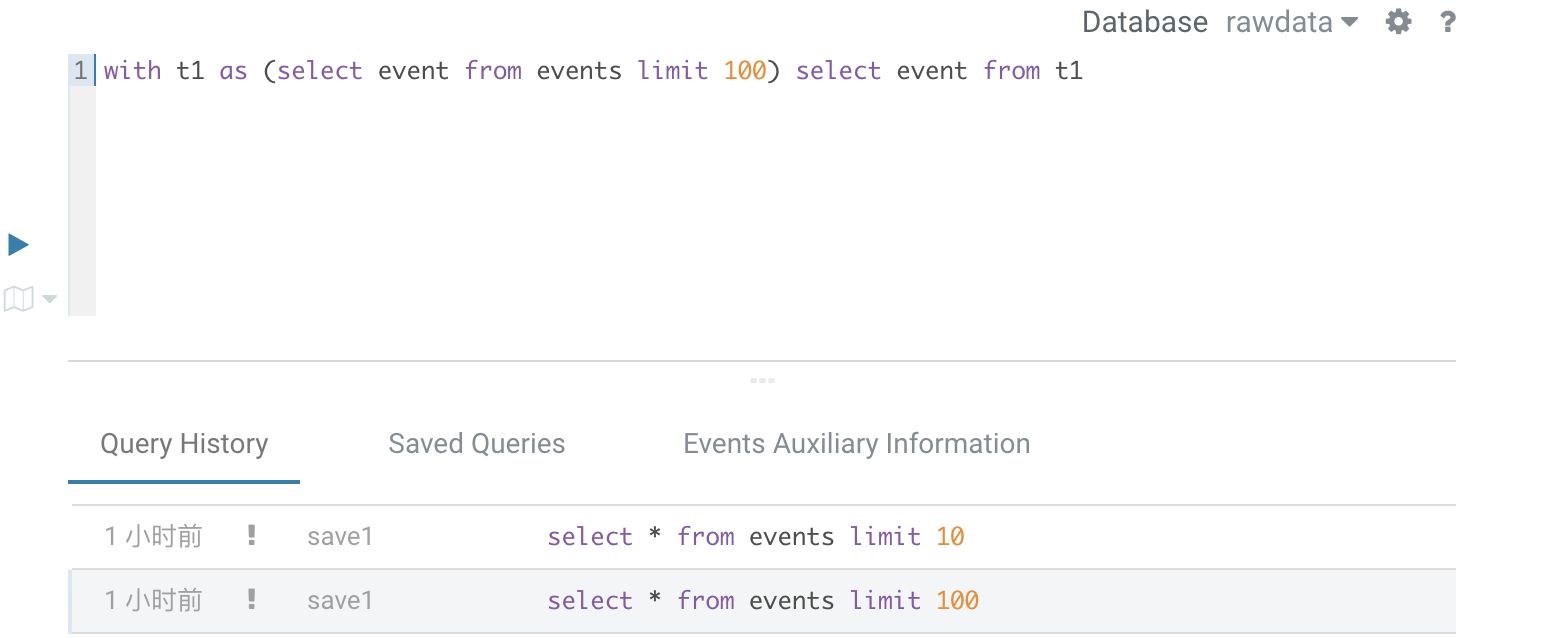
View the history of SQL queries and search the history records.
2. Advanced features
2.1. Add to report
Quickly save the current SQL query results to a report.
2.2. Intermediate Table
This is an advanced feature that is not turned on by default. Please contact operations to enable the function.
In some business scenarios, actual data results need to go through complex calculations before they can be displayed on the result table. In addition, there are some large tables for which statistical queries can be inefficient. To solve the performance issues caused by complex queries and big data, Sensory has released the intermediate table feature.
2.2.1. Instructions for use
1. Supports creating intermediate tables by creating new queries, or saving existing queries or intermediate tables as intermediate tables.
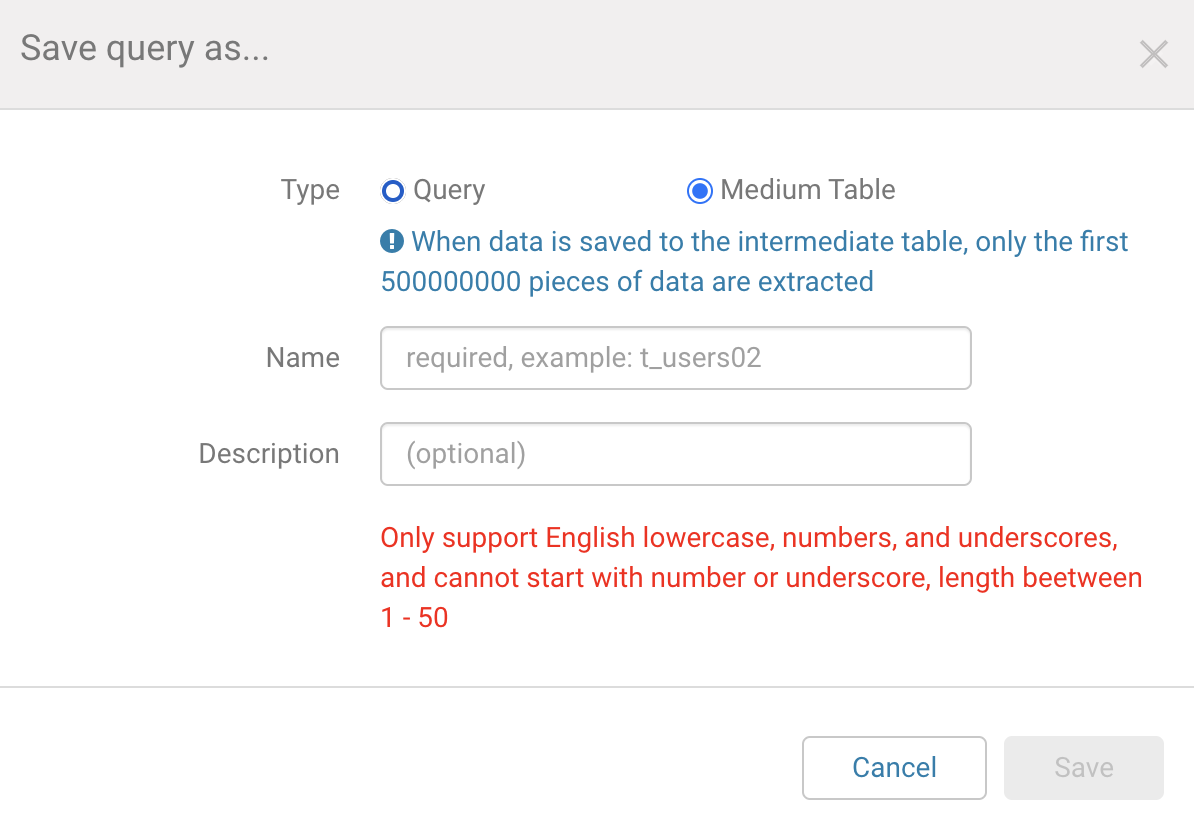
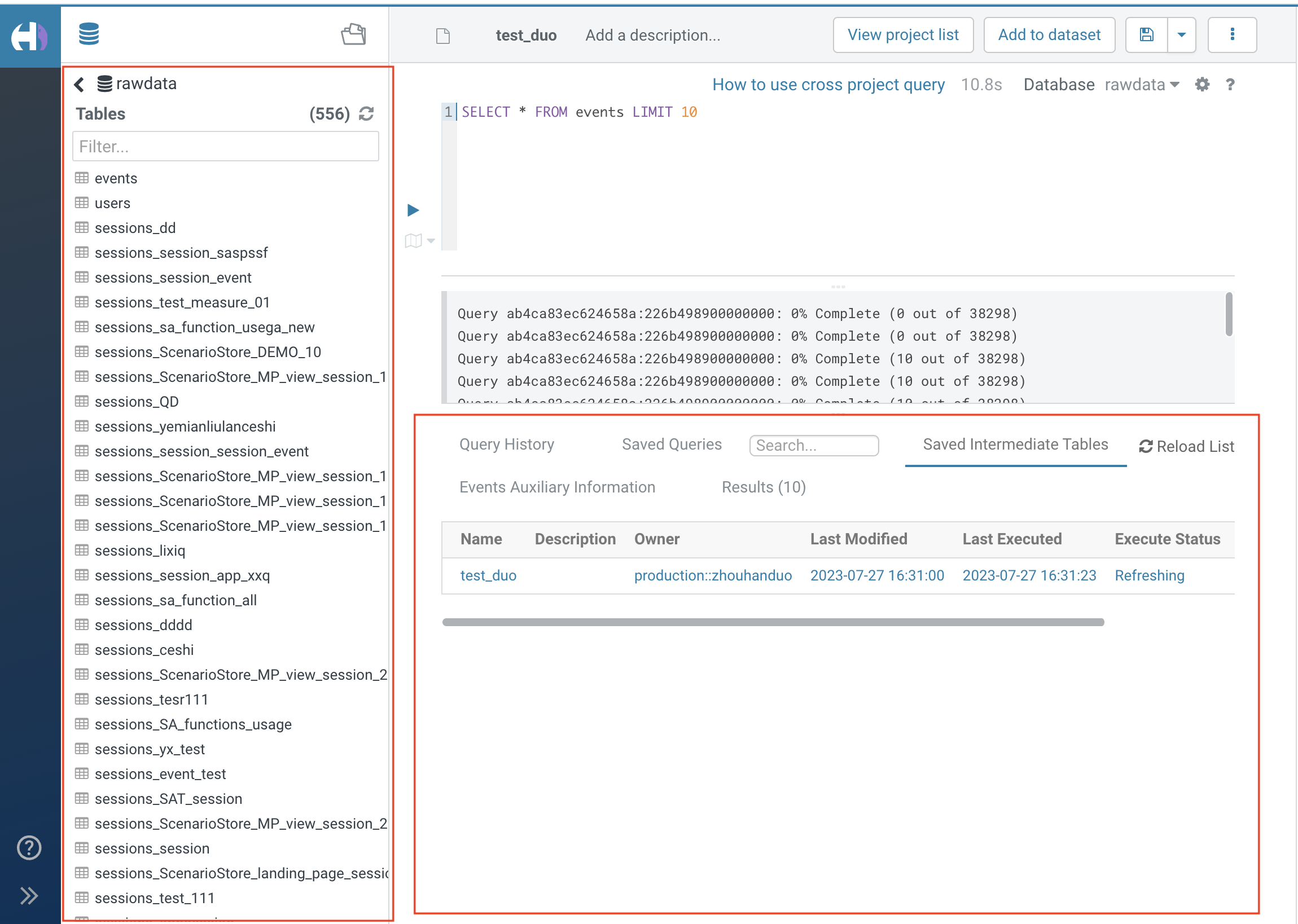
2. For reasons of query efficiency, there are some limitations to the use of custom queries in intermediate tables. The details are as follows:
- Support intermediate tables can be created from EUI tables, third-party tables, session tables, and intermediate tables, but not from user group tables or tag tables.
Select * statements query is not advised be saved as intermediate tables.
Cross-project intermediate table creation is not supported.
Preview mode does not support saving intermediate tables.
When the query result is ≥ 1, it can be saved as an intermediate table. If the query result exceeds limit records, only the first limit records will be saved to the intermediate table (default is 1 million, can be configured by contacting customer support).
A maximum of 10 tables can be saved per account per project, and intermediate tables are only visible, editable and deletable by the creator.
Intermediate tables are for temporary use only and not automatically refreshed. Users need to manually refresh the data in Hue when using it.
2.2.2. Usage example
How to create metrics using session tables: Include /*SESSION_TABLE_DATE_RANGE=[2018-01-01,2018-01-05]*/ in the query statement.
/*event表和session表创建中间表示例*/ SELECT sessions_session.event, sessions_session.user_id, sessions_session.distinct_id, sessions_session.`date`, EVENTS.showEntrance, EVENTS.action_type FROM EVENTS JOIN sessions_session ON sessions_session.user_id = events.user_id/*SESSION_TABLE_DATE_RANGE=[2018-01-01,2018-01-05]*/ where events.`date` between '2022-03-21' and '2022-03-27'SQL
2.3. Cross-project Query
This feature is advanced and not enabled by default. Please contact operations to enable the feature.
Note: This function has a dependency on lumen, you need to check lumen adaptation
2.3.1. Scene example
In the game industry, for example, customers store the data for the Find the Difference game in Project 1, the data for the Jigsaw Puzzle game in Project 2, and the data for the Strategy Card Gaming game in Project 3. The Find the Difference and Jigsaw Puzzle games are mainly used to drive traffic to the Strategy Game. The cross-project query can meet the following scenarios:
Scenario One: Viewing Large Amounts of Data: Management can view the summary data of three types of games, including daily activity, retention, and recharge, in one report. The steps are as follows:
- The successful contact with the customer begins the cross-project query function.
- Understand the English name and project ID of the required project, and the table structure inside the project.
- In the custom analysis, write a query statement, execute the query, and save the query results to the DataSet.
- In the report, select New Report, and select the business model to configure the report dashboard.
Scenario Two: Data Analysis: The user analyzes the conversion of Project One/Project Two to Project Three, etc. The steps are as follows:
- The successful contact with the customer begins the cross-project query function.
- Understand the project name required, as well as the table structure inside the project.
- In the custom analysis, write a query statement, execute the query, and download the analysis results to the local or create a report.
2.3.2. Instructions
Sorry, cross-project queries are still in the trial phase, and the process of obtaining the table structure of the project is a bit cumbersome.
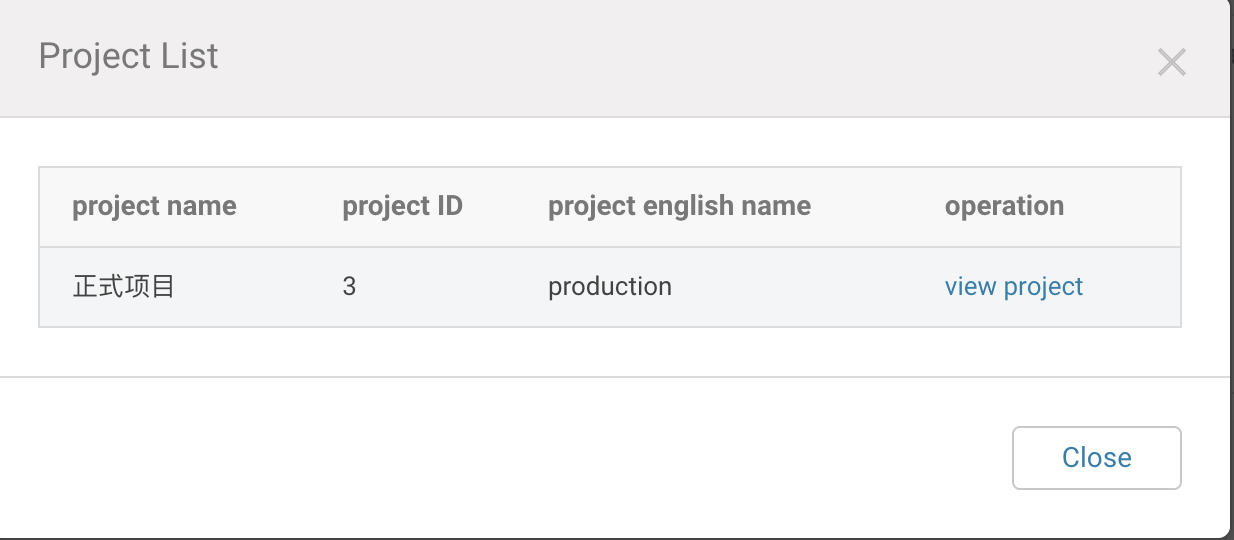
1. How to obtain the English name and project ID of the project I have access to: Click the "View Project List" in the upper right corner of the page to pop up the project list window. Support viewing the project name, project ID, English name, and operation that the user has permission to operate, and click the view project in the operation column to open the corresponding project page.

2. How to understand the table structure in each project: At present, only switching to a specific project and entering the custom query page can be viewed.
3. When do I need to specify the project to which the data table belongs: When writing an SQL statement that allows cross-project query data, you need to specify the project to which the queried Sensorsdata‘s data table belongs.
The rawdata events users items tables, user groups, tags, and session tables can use the fixed prefix "horizon" + "_${projectName}_${projectId}" to describe the data table and highlight the owner project. Take Project name "production" and Project ID "2" as an example (The project prefix here restricts the db):
- horizon_production_2.events
- horizon_production_2.users
- horizon_production_2.items
- ...
Other data tables, reports, and intermediate tables have their own dbs. You can use the format db.table name to directly use them.
- governor_production.order_detail
- blitzreport_db.daily_operation_report
- hue_medium_table_production.mothers_day_activities
- ...
2.3.3. Example of usage: Below are specific examples of cross-project queries:
- Use UNION/UNION ALL to display the intersection and union of the query results of two projects
- For example, view the number of "App installation" events performed every day in two projects since December
SELECT 'production' as project, date, count(1)
FROM horizon_production_2.events
WHERE event like 'AppInstall' and `date` > '2022-12-01'
GROUP BY 1,2
UNION ALL
SELECT 'default' as project, date, count(1)
FROM horizon_default_1.events
WHERE event = 'AppInstall' and `date` > '2022-12-01'
GROUP BY 1,2- Use JOIN to perform a joint query on the two projects' data tables
- For example, view the total number of "AppClicks" performed in the user groups of "user_group_user_group_1" under the project with "projectId=1, projectName=default" on the current day in the project with "projectId=2, projectName=production"
SELECT count(1)
FROM horizon_production_2.events events
INNER JOIN horizon_default_1.user_group_user_group_1 user_group1 ON events.user_id = user_group1.user_id
WHERE event = 'AppClick' and `date` = CURRENT_DATE()- For example, view the data of "date, distinct_id, `$element_target_url`, `$country`, `$utm_campaign`" in the "event" of the project with "projectId=1, projectName=zwp_001_3." under the only day in the project with "projectId=2, projectName=production"
SELECT e1.event,
e2.date,
e2.distinct_id,
e2.`$element_target_url`,
e2.`$country`,
e2.`$utm_campaign`
FROM horizon_production_2.events e1
LEFT JOIN horizon_zwp_001_3.events e2 ON e1.event = e2.event2.4. Data Desensitization
This is an advanced feature that is not turned on by default, and you need to contact the operations team to turn it on.
According to the SBP data permission and desensitization attribute configuration page of the logged-in user, configure the fields that need to be desensitized for the event attributes or user attributes that need to be desensitized, pre-verify the desensitized fields in the sql statement written in the hue interface.
【Currently, there is no distinction for desensitization display, prohibited grouping, and filtering. If de-sensitization properties are involved in SQL, an error will occur directly.】
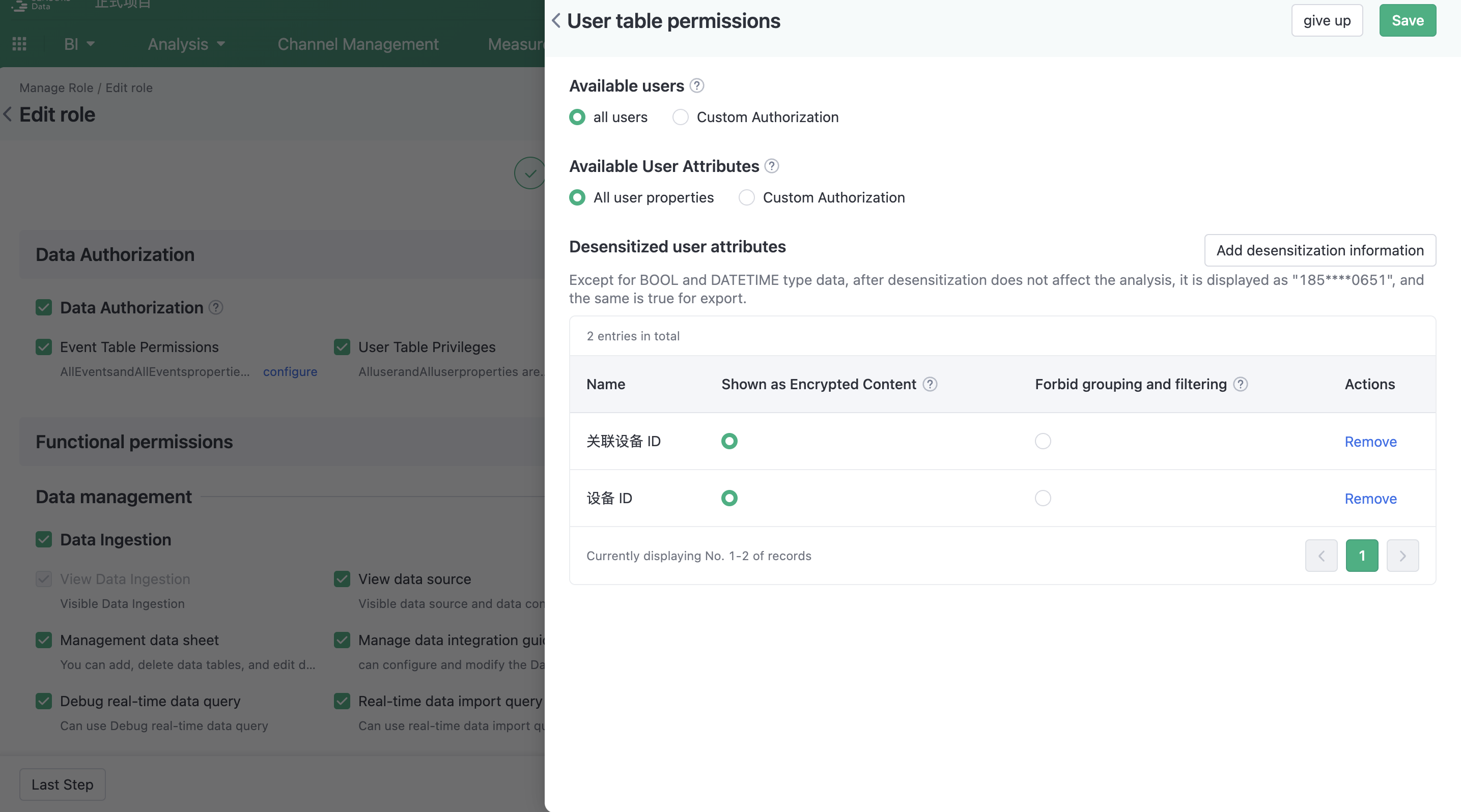
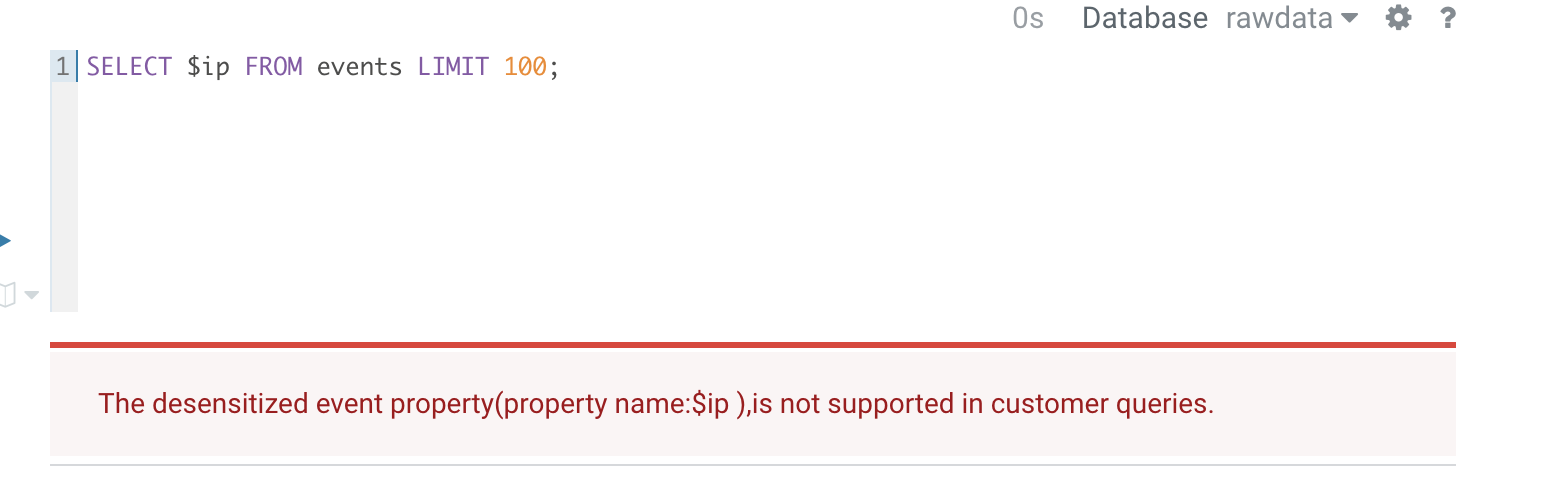
Current status of SQL parsing:
- Support SELECT statements, including: Select, From, Where, Group By, Order By
- Support subquery after FROM and WHERE (consistent with Impala)
- Subqueries nested in subqueries after WHERE are not supported for now, for example: where column=(select xxx from (...) t where...)
- FROM cannot have multiple subqueries at the same level for now, for example: from (...) a, (...) b
- Support multiple tables or a subquery after FROM
2.5. Meta Event Auxiliary Information
Support viewing meta event auxiliary information. By default, all events are displayed. Click on the "Event Name" or "View" in the operation column to view the attribute list corresponding to the event. Support copying the event name and attribute name, and manually paste it (ctrl+v or right-click → paste) into the SQL editing area
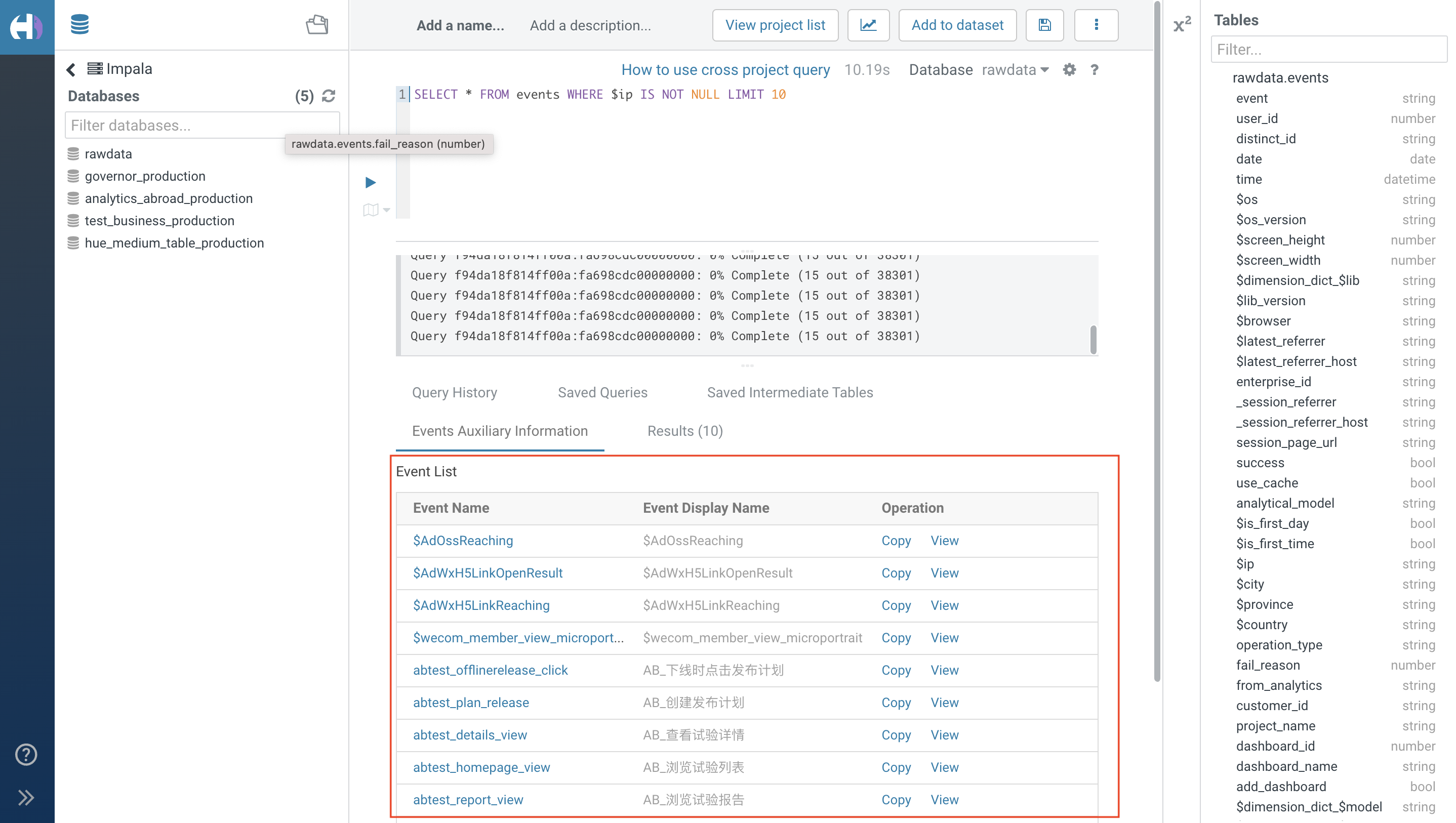
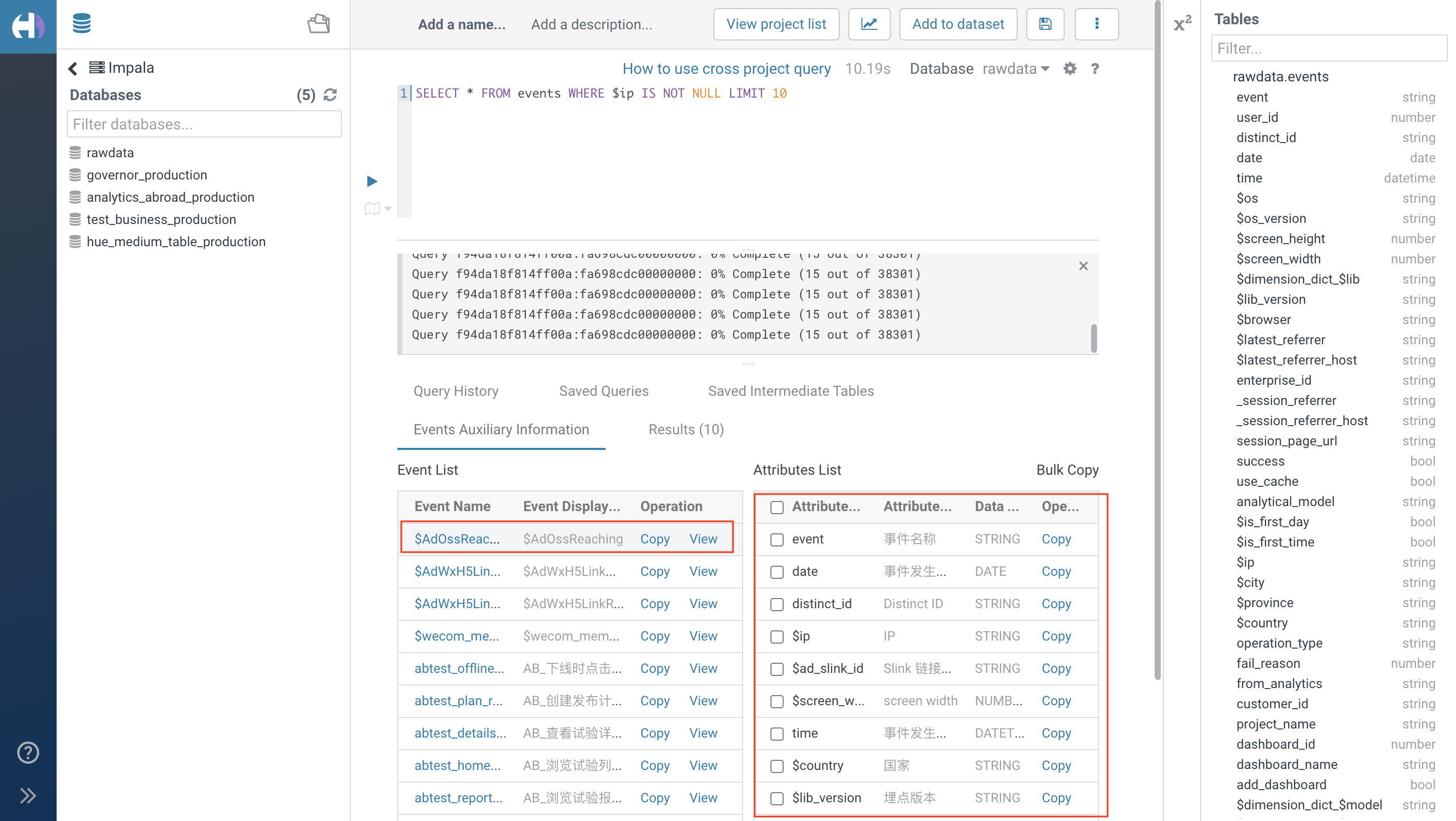
3. Date Filter
The date field represents the date when the event occurred, with a granularity of a day. It can be used to filter the data quickly. It should be noted that the date field should be used for filtering at all times, instead of the time field.
Due to the uniqueness of the date field, there are some restrictions on the support for SQL operations and functions. Currently, the functions and expressions that can be used include:
- The CURRENT_DATE() function, which returns the current day, such as 2016-08-23.
- The CURRENT_WEEK() function, which returns the Monday of the current week, such as 2016-08-22.
- The CURRENT_MONTH() function, which returns the first day of the current month, such as 2016-08-01.
- The INTERVAL expression, such as
CURRENT_DATE() - INTERVAL '1' DAYwhich represents yesterday.
Here are some specific examples:
- Filter data for a specific day.
SELECT COUNT(*) FROM events WHERE date = '2016-01-01'- Query data for the current day.
SELECT COUNT(*) FROM events WHERE date = CURRENT_DATE()- Query data for the last three days.
SELECT COUNT(*) FROM events WHERE date BETWEEN CURRENT_DATE() - INTERVAL '2' DAY AND CURRENT_DATE()- Query data for the previous natural month.
SELECT COUNT(*) FROM events WHERE date BETWEEN CURRENT_MONTH() - INTERVAL '1' MONTH AND CURRENT_MONTH() - INTERVAL '1' DAYDue to the special nature of the date field, which is designed for fast data filtering, it does not support most time functions. Therefore, if you want to use other time functions, replace the date field with the time field, as follows:
SELECT datediff(now(), trunc(time, 'DD')), COUNT(*) FROM events WHERE date >= CURRENT_DATE() - INTERVAL '100' day GROUP BY 1- Aggregate the number of events after 2018-09-01 by month.
SELECT date_sub(date,dayofmonth(date)-1) the_month,count(*) event_qty
FROM events WHERE date>'2018-09-01'
GROUP BY the_month ORDER BY the_month;- Aggregate the number of events after 2018-09-01 by week.
SELECT date_sub(date,mod(dayofweek(date)+5,7)) the_week,count(*) event_qty
FROM events WHERE date>'2018-09-01'
GROUP BY the_week ORDER BY the_week;4. Advanced Options
- Enabling fast Distinct algorithms can greatly speed up calculations such as COUNT(DISTINCT user_id), and support multiple COUNT(DISTINCT) expressions (version 1.17 or later). The disadvantage is that the results obtained may not be completely accurate. Example:
SELECT COUNT(DISTINCT user_id) FROM events
WHERE date = CURRENT_DATE() /*ENABLE_APPROX_DISTINCT*/- Enable dimension dictionary mapping and dimension table association, which is disabled by default. Example:
SELECT $model FROM events
WHERE date = CURRENT_DATE() /*ENABLE_DIMENSION_DICT_MAPPING*/- You can use this option to query data for a specified distinct_id. Example:
SELECT event, time FROM events
WHERE date = CURRENT_DATE() AND distinct_id='abcdef' /*DISTINCT_ID_FILTER=abcdef*/- By default, SQL will be forcibly killed by the system after 10 minutes. If you want to increase the timeout time, use the following method:
SELECT * FROM events WHERE date = CURRENT_DATE() LIMIT 1000 /*MAX_QUERY_EXECUTION_TIME=1800*/- For JOIN-type queries, you can use Join Hint to specify the execution mode of JOIN, which can be SHUFFLE or BROADCAST. In particular, if you encounter an out-of-memory error during execution, you can consider forcing it to SHUFFLE mode:
SELECT COUNT(*) AS cnt FROM events
JOIN /* +SHUFFLE */ users ON events.user_id = users.id
WHERE date = CURRENT_DATE()5. Common Scenarios
5.1. Query the specific behavior of a user on a certain day based on the user's distinct_id.
Just use distinct_id for query:
SELECT * FROM events WHERE distinct_id = 'wahaha' AND date = '2015-09-10' LIMIT 1005.2. Query the number of users placing orders from 10 am to 11 am every day.
Use standard SQL date function EXTRACT to extract hour information.
SELECT date,
COUNT(*) FROM events WHERE EXTRACT(HOUR FROM time) IN (10, 11) AND event = 'SubmitOrder'
GROUP BY 15.3. Query the distribution of user order frequency during a certain period of time.
First calculate the order frequency of each user, and then use CASE..WHEN syntax to group them.
SELECT
CASE
WHEN c < 10 THEN '<10'
WHEN c < 20 THEN '<20'
WHEN c < 100 THEN '<100'
ELSE '>100'
END,
COUNT(*)
FROM (
SELECT user_id, COUNT(*) AS c FROM events
WHERE date BETWEEN '2015-09-01' AND '2015-09-20' AND event = 'SubmitOrder'
GROUP BY 1
)a
GROUP BY 15.4. Query the number of users who have done behavior A but not behavior B.
Use LEFT OUTER JOIN to calculate the difference set.
SELECT a.user_id FROM (
SELECT DISTINCT user_id FROM events WHERE date='2015-10-1' AND event = 'BuyGold' ) a
LEFT OUTER JOIN (
SELECT DISTINCT user_id FROM events WHERE date='2015-10-1' AND event = 'SaleGold' ) b
ON a.user_id = b.user_id
WHERE b.user_id IS NULL5.5. Calculate the user's usage time.
Use analysis functions to estimate cumulative usage time based on the interval between two adjacent events for each user. If the interval exceeds 10 minutes, it will not be calculated.
SELECT
user_id,
SUM(
CASE WHEN
end_time - begin_time < 600
THEN
end_time - begin_time
ELSE
0
END
) FROM (
SELECT
user_id,
EXTRACT(EPOCH FROM time) AS end_time,
LAG(EXTRACT(EPOCH FROM time), 1, NULL) OVER (PARTITION BY user_id ORDER BY time asc) AS begin_time
FROM events
WHERE date='2015-5-1'
) a
GROUP BY 15.6. Get users' first behavior attributes.
Use the first_time_value (time, other attributes) aggregate function to obtain the relevant attributes when the behavior occurs for the first time.
-- Example 1: Get the URL of the page where the user finished the first page view.
SELECT user_id, first_time_value(time, $url) FROM events WHERE event = '$pageview' GROUP BY user_id
-- Example 2: Get the amount of money purchased when the user makes the first purchase
SELECT user_id, first_time_value(time, order_amount) first_order_amount FROM events WHERE event = 'payOrder' GROUP BY user_id5.7. Get the dimension dictionary uploaded in metadata management.
If the attribute has a dimension dictionary, the customer needs to add an SQL comment /*ENABLE_DIMENSION_DICT_MAPPING*/ manually.
SELECT DISTINCT orgName
FROM users /*ENABLE_DIMENSION_DICT_MAPPING*/;6. Incompatible syntax changes
The custom query engine has been switched to direct query mode and the underlying query engine version has been upgraded to 4.8, so there are a few incompatible syntax changes.
- The events.date field is changed to datetime type and no longer supports number type calculations such as + - * /.
/* Supported Syntaxes */
SELECT * FROM events WHERE date = '2021-03-01' + interval 1 day
/* Unsupported syntax */
SELECT * FROM events WHERE date - 1 = '2021-03-01'- When using the events.date field for two table joins, due to the type change of the date field, depending on the number of data rows joined, there may be varying degrees of decline in query performance. This method cannot be avoided for the time being, and we will consider rewriting this condition in subsequent versions to avoid calculating functions every time. It is recommended to avoid the events.date field participating in Join operations as much as possible in scenarios where performance is particularly sensitive. For example:
/* Usage with performance loss */
SELECT *
FROM
(
FROM
*
FROM
events
WHERE
date = '2021-01-02'
) a
LEFT JOIN (
SELECT
*
FROM
users
) b ON a.date = b.birthday- In GROUP BY, HAVING, and ORDER BY, the alias replacement logic is more consistent with standard SQL behavior, where aliases are only valid for top-level expressions and not for sub-expressions. For example:
/* Supported Syntaxes */
SELECT NOT bool_col AS nb
FROM t
GROUP BY nb
HAVING nb;
/* Unsupported Syntaxes */
SELECT int_col / 2 AS x
FROM t
GROUP BY x
HAVING x > 3;- A series of reserved fields are added, which cannot be used directly as identifiers. If you need to use them as identifiers, you must enclose them in backticks, for example:
/* Supported Syntaxes */
SELECT `position` FROM events
/* Unsupported Syntaxes */
SELECT position FROM events- The newly added reserved fields include:
| allocate, any, api_version, are, array_agg, array_max_cardinality, asensitive, asymmetric, at, atomic, authorization, begin_frame, begin_partition, blob, block_size, both, called, cardinality, cascaded, character, clob, close_fn, collate, collect, commit, condition, connect, constraint, contains, convert, copy, corr, corresponding, covar_pop, covar_samp, cube, current_date, current_default_transform_group, current_path, current_role, current_row, current_schema, current_time, current_transform_group_for_type, cursor, cycle, deallocate, dec, decfloat, declare, define, deref, deterministic, disconnect, dynamic, each, element, empty, end-exec, end_frame, end_partition, equals, escape, every, except, exec, execute, fetch, filter, finalize_fn, foreign, frame_row, free, fusion, get, global, grouping, groups, hold, indicator, init_fn, initial, inout, insensitive, intersect, intersection, json_array, json_arrayagg, jso, n_exists, json_object, json_objectagg, json_query, json_table, json_table_primitive, json_value, large, lateral, leading, like_regex, listagg, local, localtimestamp, log10, match, match_number, match_recognize, matches, merge, merge_fn, method, modifies, multiset, national, natural, nchar, nclob, no, none, normalize, nth_value, nth_value, occurrences_regex, octet_length, of, off, omit, one, only, out, overlaps, overlay, pattern, per, percent, percentile_cont, percentile_disc, portion, position, position_regex, precedes, prepare, prepare_fn, procedure, ptf, reads, recursive, ref, references, regr_avgx, regr_avgy, regr_count, regr_intercept, regr_r2, regr_slope, regr_sxx, regr_sxy, regr_syy, release, rollback, rollup, running, savepoint, scope, scroll, search, seek, serialize_fn, similar, skip, some, specific, specifictype, sqlexception, sqlwarning, static, straight_join, submultiset, subset, substring_regex, succeeds, symmetric, system_time, system_user, timezone_hour, timezone_minute, trailing, translate_regex, translation, treat, trigger, trim_array, uescape, unique, unnest, update_fn, value_of, varbinary, varying, versioning, whenever, width_bucket, window, within, without |
Note: The content of this document is a technical document that provides details on how to use the Sensors product and does not include sales terms; the specific content of enterprise procurement products and technical services shall be subject to the commercial procurement contract.
 Popular Searches
Popular Searches