Integration Documentation (Java)
|
Collect
1. Integrating Sensors Analytics SDK in Your Project
The Java SDK has been open sourced on GitHub, with the link: https://github.com/sensorsdata/sa-sdk-java. It is also published in the Maven Central Repository. You can choose from the following methods to integrate:
The latest version of the Sensors Analytics Java SDK supports minimum JDK version of JDK 1.7 and above.
1.1. Integration using Maven
<dependencies> <!-- 引入神策分析 SDK --> <dependency> <groupId>com.sensorsdata.analytics.javasdk</groupId> <artifactId>SensorsAnalyticsSDK</artifactId> <version>3.4.3</version> </dependency> </dependencies>1.2. Integration using Gradle
dependencies { compile 'com.sensorsdata.analytics.javasdk:SensorsAnalyticsSDK:3.4.3' }1.3. Dependency on Local Library
If your project does not use any jar package management tool, you can choose to download the specified release version from GitHub here and use it as a local dependency.
2. Initializing Sensors Analytics SDK
The Java SDK mainly consists of the following two components:
- ISensorsAnalytics: The top-level interface object that exposes data generation, and its constructor requires a consumer instance object.
- Consumer: Provides data sending mechanisms with different capabilities.
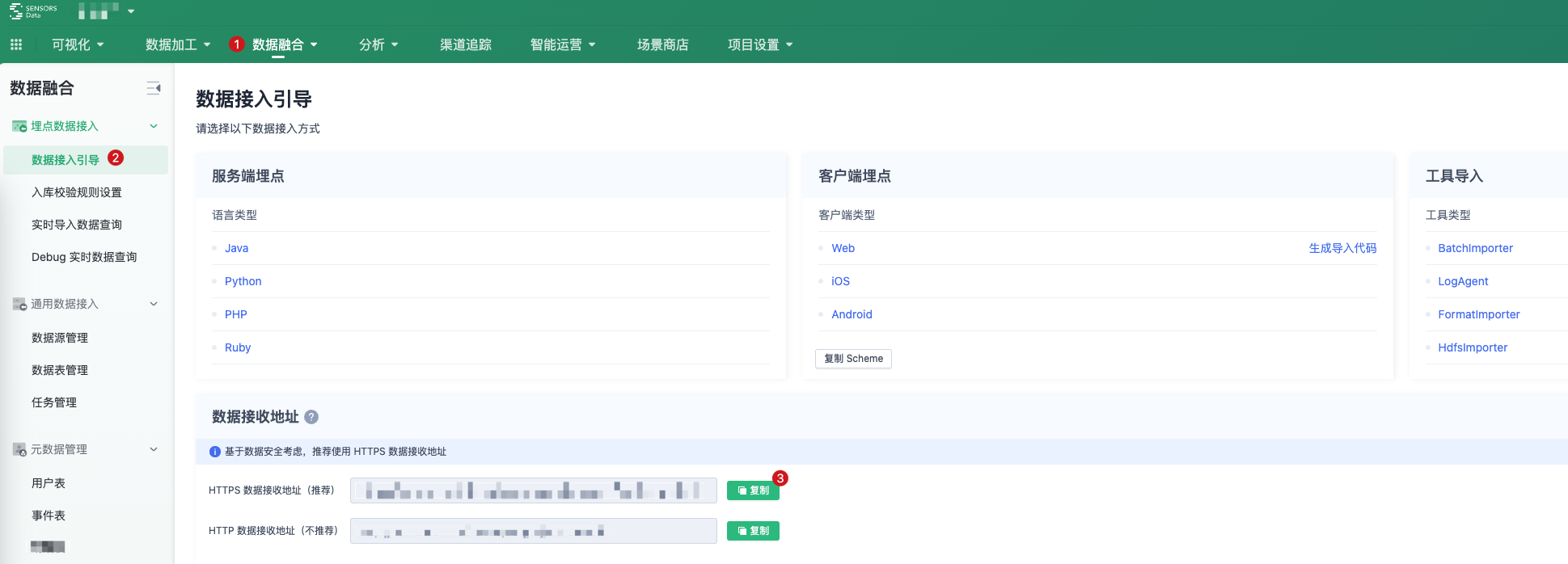
2.1. Getting Data Receiving URL
Refer to the following diagram to obtain the data receiving URL:
2.2. Initializing the SDK
Because the initialization operation of the SDK creates a corresponding memory cache queue, please be cautious when creating SDK instances. It is recommended to initialize it once globally when the application starts, and then make global calls. Avoid initializing SDK instances inside methods, creating multiple instances during program execution, and causing OOM.
In many customer use cases, we have observed that incorrect usage of the SDK affects the performance of the overall business logic. Therefore, after completing the initialization according to the official website tutorial, it is not recommended to actively call the flush operation during the log collection process. The flush operation will be triggered internally by the SDK.
If you perform the flush operation after each track, the internal cache queue will become invalid. Under high concurrency, frequent lock contention will occur, leading to a decrease in service performance.
2.2.1. Initializing the SDK in a regular Java program
During program startup (such as public static void main(String[] args) method), call the constructor new SensorsAnalytics(Consumer) to initialize the Java SDK (need to initialize globally only once)
// 使用 ConcurrentLoggingConsumer 初始化 SensorsAnalytics final SensorsAnalytics sa = new SensorsAnalytics(new ConcurrentLoggingConsumer("您的日志文件路径")); // 用户的 Distinct ID String distinctId = "ABCDEF123456789"; // 记录用户登录事件 EventRecord loginRecord = EventRecord.builder().setDistinctId(distinctId).isLoginId(Boolean.TRUE) .setEventName("UserLogin") .build(); sa.track(loginRecord); // 使用神策分析记录用户行为数据 // ...2.2.2. To initialize the SDK in the Spring framework
If your project uses the Spring framework, it is recommended to configure the initialization operation as a bean and let the Spring container manage it. Inject it into the class to use it.
2.2.2.1. Creating Bean objects using annotations
@Configuration public class SensorsConfig { @Bean(destroyMethod = "shutdown") public ISensorsAnalytics init() throws IOException { //本地日志模式(此模式会在指定路径生成相应的日志文件) return new SensorsAnalytics(new ConcurrentLoggingConsumer("您的日志文件路径")); //debug 模式(此模式只适用于测试集成 SDK 功能,千万不要使用到生产环境!!!) //return new SensorsAnalytics(new DebugConsumer("数据接收地址", true)); //网络批量发送模式(此模式在容器关闭的时候,如果存在数据还没有发送完毕,就会丢失未发送的数据!!!) //return new SensorsAnalytics(new BatchConsumer("数据接收地址")); } }2.2.2.2. Creating Bean objects using XML configuration files
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.2.xsd"> <!-- 本地日志模式(此模式会在指定路径生成相应的日志文件) --> <bean id="loggingConsumer" class="com.sensorsdata.analytics.javasdk.consumer.ConcurrentLoggingConsumer"> <constructor-arg name="filenamePrefix" value="您的日志文件路径"/> </bean> <!-- debug 模式(此模式只适用于测试集成 SDK 功能,千万不要使用到生产环境!!!) --> <!--<bean id="debugConsumer" class="com.sensorsdata.analytics.javasdk.consumer.DebugConsumer"> <constructor-arg name="serverUrl" value="数据接收地址"/> <constructor-arg name="writeData" value="true"/> </bean>--> <!-- 网络批量发送模式(此模式在容器关闭的时候,如果存在数据还没有发送完毕,就会丢失未发送的数据!!!)--> <!--<bean id="batchConsumer" class="com.sensorsdata.analytics.javasdk.consumer.BatchConsumer"> <constructor-arg name="serverUrl" value="数据接收地址"/> </bean>--> <!-- 此处选择合适的模式进行数据采集操作(此处选择本地日志模式) --> <bean id="sensorsAnalytics" class="com.sensorsdata.analytics.javasdk.SensorsAnalytics" destroy-method="shutdown"> <constructor-arg name="consumer" ref="loggingConsumer"/> </bean> </beans>2.3. ISensorsAnalytics API Introduction
| Interface Method Name | Request Parameters | Response Parameters | Description |
|---|---|---|---|
| setEnableTimeFree | boolean true: Enable historical data import mode, default is disabled | void | Enable historical data import mode |
registerSuperProperties | SuperPropertiesRecord: Entity for common properties | void | Set global common properties for event properties to avoid adding them to individual events |
clearSuperProperties | - | void | Clear global public properties settings |
track | EventRecord: Entity for event information, filling user behavior attribute records | void | Record user behavior tracking operation |
trackSignUp |
| void | Record the operation of binding anonymous user to login ID, used to identify the behavior sequence before and after user login |
| profileSet | UserRecord: Entity for user information, filling user attribute records | void | Record the attribute information of a single user |
| profileSetOnce | UserRecord: Entity for user information, filling user attribute records | void | Set user attribute for the first time; different from the profileSet interface: if the attribute already exists in the user's profile, it will not be processed, otherwise, it will be created |
| profileIncrement | UserRecord: Entity for user information, fills in user attribute records | void | Increment a numerical value for one or more numerical type attributes of a specified user. If the attribute does not exist, create it and set the default value to 0. Only accepts Number type for attribute values |
| profileAppend | UserRecord: Entity for user information, fills in user attribute records | void | Append a string to one or more array type attributes of a specified user. The attribute value must be of java.util.List type, and the element type in the list must be String |
| profileUnset | UserRecord: Entity for user information, fills in user attribute records | void | Delete one or more attributes that exist for a specified user |
| profileDelete | UserRecord: Entity for user information, fills in user attribute records | void | Delete all attributes for a specified user |
| itemSet | ItemRecord: Entity for dimension table information | void | Add item records |
| itemDelete | ItemRecord: Dimension table information entity | void | Delete item |
| flush | - | void | Immediately send all logs in the cache (Do not call this method actively when not in debug mode or when the program is closed) |
| shutdown | - | void | Stop all threads of SensorsDataAPI, and all local data will be cleared before the API stops. |
3. SDK Consumer Introduction
3.1. DebugConsumer
Used to verify if the SDK is integrated correctly and if the data is sent to the Sensors Analytics server successfully.
Because the Debug mode is provided to verify the integration of the SDK and the normal transmission of data to the Sensors Analytics server, this mode verifies the data item by item and throws exceptions when the verification fails. Its performance is much lower than the normal mode.
It is only applicable to local debugging environments. It should not be used for any online services.
Explanation of construction parameters:
| Parameter name | Parameter type | Whether required | Description |
|---|---|---|---|
| serverUrl | String | Yes | Data Receiving URL |
| writeData | boolean | Yes | Whether data is stored in the database. true: data is stored; false: data is not stored (only displayed, not saved) |
Code example:
// 从神策服务器数据接入引导页面获取的数据接收的 URL String serverUrl = ""; ISensorsAnalytics sa = new SensorsAnalytics(new DebugConsumer(serverUrl,true));3.2. ConcurrentLoggingConsumer
Used to output data to the specified file directory and generate logs cut by day. Import using LogAgent and other tools. This tool can ensure that the import is not duplicated or missed. Recommended to be used in production environments. ConcurrentLoggingConsumer Import data. Supports multiple processes writing to the same directory (the directory cannot be a NAS or NFS-like file system), and the generated file always has a date suffix, with one file per day by default.
Construction parameter description:
| Parameter Name | Parameter Type | Required | Description |
|---|---|---|---|
| filenamrPrefix | String | Yes | Data saving file path |
| bufferSize | int | No | Consumer internal cache size; The default is 8192 bytes |
| lockFileName | String | No |
|
| splitMode | LogSplitMode | No | The default log cutting mode is LogSplitMode.DAY. LogSplitMode.HOUR is optional |
Code example:
// 将数据输出到 /data/sa 下的 access.log.2017-01-11 文件中,每天一个文件;对应目录文件需要自己创建,日志文件后缀会自动生成 final SensorsAnalytics sa = new SensorsAnalytics(new ConcurrentLoggingConsumer("/data/sa/access.log")); // !! 注意 !! 如果是在 Windows 环境下使用 ConcurrentLoggingConsumer 并使用 LogAgent 发送数据, // 需要额外通过构造函数的第二个参数指定一个文件地址用于文件锁,例如: // SensorsAnalytics sa = new SensorsAnalytics(new ConcurrentLoggingConsumer("D:\\data\\service", "D:\\var\\sa.lock")); // 若该文件与数据文件同目录,配置 LogAgent 的 pattern 时请不要匹配到这个文件。3.3. BatchConsumer
Sending data in bulk Consumer, when the number of data reaches the specified value (50 by default, a maximum of 1000 can be specified), the data is sent. Can also call flush() method force sending. Note: BatchConsumer will not throw an exception by default. If an exception occurs on the network, data will fail to be sent and data will be lost. If you want to get the corresponding exception information, you need to go through the initialization function BatchConsumer(final String serverUrl, final int bulkSize, final boolean throwException) set throwException parameter is true.
It is usually used when small-scale historical data is imported or data is imported offline or off-line. Because data is sent directly from the network, data may be lost if the network is abnormal. Therefore, you are not recommended to use the data on online services.
You are advised to use the network sending mode if you do not want to send abnormally lost data FastBatchConsumer mode
Construction parameter description:
| Parameter name | Parameter Type | Required | Description |
|---|---|---|---|
| serverUrl | String | Yes | Data Receiving URL |
| bulkSize | int | No | Threshold for triggering flush operation. When the memory cache queue reaches this value, the data in the cache will be batch uploaded. The default value is 50. |
| timeoutSec | int | No | Network request timeout, default is 3s. |
| maxCacheSize | int | No | Maximum cache refresh size. If it exceeds this value, the flush operation will be triggered immediately. The default value is 0, which depends on bulkSize. |
| throwException | boolean | no | Whether to throw an exception when a network request error occurs, true: throw; false: not throw; default is not to throw |
Code example:
// 从神策分析获取的数据接收的 URL final String SA_SERVER_URL = "YOUR_SERVER_URL"; // 当缓存的数据量达到50条时,批量发送数据 final int SA_BULK_SIZE = 50; // 数据同步失败不抛出异常 final boolean THROW_EXCEPTION = false; // 内存中数据最大缓存条数,如此值大于0,代表缓存的数据会有条数限制,最小 3000 条,最大 6000 条。否则无条数限制。 final int MAX_CACHE_SIZE = 0; // 使用 BatchConsumer 初始化 SensorsAnalytics // 不要在任何线上的服务中使用此 Consumer final SensorsAnalytics sa = new SensorsAnalytics(new BatchConsumer(SA_SERVER_URL, SA_BULK_SIZE, MAX_CACHE_SIZE, THROW_EXCEPTION));3.4. FastBatchConsumer
针对 BatchConsumer 模式的一种优化模式,通过提供回调函数收集发送失败的数据。
The callback function collects the data that fails to be put into the cache and the data that fails to be sent during the network request process. Starting from version 3.4.0, the resendFailedData() interface is provided to resend the failed data.
FastBatchConsumer creates a new thread to consume the data in the cache, so it will not block the main thread operation; if it is initialized in the interface, it will create an infinite number of consumer threads, leading to system resource tension, so please be sure to initialize it once globally!
Construction parameter description:
| Parameter name | Parameter type | Is it required | Description |
|---|---|---|---|
| serverUrl | String | yes | Data receiving URL |
| timing | boolean | No | Consumer thread runtime, true: indicates that the consumer thread runs periodically to execute the flush operation (setting this value will make bulkSize ineffective); false: indicates that the consumer thread runs periodically to check if the cache queue reaches the bulkSize and perform the flush operation |
| bulkSize | int | No | Threshold for triggering the flush operation. When the memory cache queue reaches this value, the data in the cache will be reported in batches. Default is 50 |
| timeoutSec | int | No | Network request timeout period. Default is 3 seconds |
| maxCacheSize | int | No | Maximum number of records to be saved in the memory cache queue. Default is 6000, with an upper limit of 10000 and a lower limit of 1000 |
| flushSec | int | No | Frequency at which the consumer thread periodically executes. Default is 1 second |
| callback | Callback | Yes | Callback function returns failed data;Version 3.4.5 optimizes the returned data. Before this version, all data in the cache was returned (including successfully sent and failed data); Version 3.4.5 optimizes it to only return the batch of data that failed to send; For example, there are 100 pieces of data divided into two batches for reporting. If the first batch fails to report and the second batch succeeds, the callback function will only return the first 50 pieces of data; |
Code example:
//发送失败的数据,收集容器。(仅测试使用,避免网络异常时,大批量数据发送失败同时保存内存中,导致 OOM ) final List<FailedData> failedDataList = new ArrayList<>(); //参数含义:数据接收地址,是否定时上报,非定时上报阈值触发条数,内部缓存最大容量,定时刷新时间间隔,网络请求超时时间,请求失败之后异常数据回调 //提供多重构造函数,可以根据实际去调用不同的构造函数 final FastBatchConsumer fastBatchConsumer = new FastBatchConsumer("serviceUri", false, 50, 6000, 2, 3, new Callback() { @Override public void onFailed(FailedData failedData) { //收集发送失败的数据 failedDataList.add(failedData); } }); //构建 sa 实例对象 final SensorsAnalytics sa = new SensorsAnalytics(fastBatchConsumer); //do something track event sa.track(EventRecord.builder().build()); //异常数据的重发送设置(重发送尽量由另外一个单独的线程来处理完成,避免影响主线程处理逻辑) if (!failedDataList.isEmpty()) { for (FailedData failedData : failedDataList) { try { //返回重发送接口发送成功与否,true:发送成功;false:发送失败 boolean b = fastBatchConsumer.resendFailedData(failedData); } catch (Exception e) { //处理重发送数据校验异常的情况 e.printStackTrace(); } } }3.5. ConsoleConsumer
Used to output data to a specific Writer, generally used to process historical data in Java programs in production environment, generate log files, and import using Integrator Importer Documentation and other tools
Constructor parameter description:
| Parameter Name | Parameter Type | Required | Description |
|---|---|---|---|
writer | Writer | Yes | Specify the Writer |
Code example:
// 将数据输出到标准输出 final Writer writer = new PrintWriter(System.out); // 使用 ConsoleConsumer 初始化 SensorsAnalytics final SensorsAnalytics sa = new SensorsAnalytics(new ConsoleConsumer(writer)); // 使用神策分析记录用户行为数据 // ... // Flush the writer writer.flush();3.6. LoggingConsumer (not recommended)
Not recommended for use in production environments due to potential file splitting issues in multi-processes; Recommended to switch to ConcurrentLoggingConsumer according to customer advice; Here are the steps to switch: ConcurrentLoggingConsumer;
4. API Interface
For the usage documentation of the API interface, refer to the Basic API Documentation.
Note: The content of this document is a technical document that provides details on how to use the Sensors product and does not include sales terms; the specific content of enterprise procurement products and technical services shall be subject to the commercial procurement contract.
 Popular Searches
Popular Searches