Using JDBC for data access
|
Collect
The content described in this document belongs to the advanced usage of Sensors Analytics, involving many technical details, and is applicable to experienced users who are familiar with related functions. If you have any doubts about the content of the document, please consult the on-duty classmates of Sensors Analytics for one-on-one assistance.
1. Overview
In Sensors Analytics' stand-alone and cluster versions, we provide a more efficient and stable SQL query method, which is to directly use JDBC or impala-shell for data querying. For specific instructions on how to connect to Impala using JDBC, you can directly refer to the official documentation.
2. Usage
2.1. Steps for usage
2.1.1. Get the JDBC address
- Login to any Sensors server
- Switch to sa_cluster account
su - sa_cluster- Use the following command to get the address
spadmin config get client -m impala -p sparadmin config get client -p sp -m impalaFor example, the output is:
{ "hive_url_list": [ "jdbc:hive2://192.168.1.2:21050/rawdata;auth=noSasl", "jdbc:hive2://192.168.1.3:21050/rawdata;auth=noSasl", ], "hive_user": "sa_cluster" }Among them, any address in hive_url_list can be used for connection.
2.1.2. JDBC link access
If using code to access, we recommend using version 1.1.0 of the Hive JDBC Driver for access. The Maven dependency definition is as follows:
<dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>1.1.0</version> </dependency>Note: In actual code execution, the Hive JDBC Driver will depend on other jar packages, mainly hadoop-common, hive-service, hive-common, and libthrift. Normally, these jar packages will be automatically obtained. If they are not automatically obtained, you need to add the corresponding jar packages, or check if the corresponding package is excluded in the pom. You can check if there is a similar configuration in the code:
<exclusions> <exclusion> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> </exclusion> <exclusion> <groupId>org.apache.hive</groupId> <artifactId>hive-service</artifactId> </exclusion> </exclusions>If the package has been imported, but other errors occur, it may be caused by package conflicts and package arrangement is required.
In addition, Impala also supports the use of officialImpala JDBC Driver To access, but in order to be compatible with the sensors analytics system, please be sure to enable Native SQL options when using, such as:
jdbc:impala://192.168.1.1:21050/rawdata;UseNativeQuery=1Note: The JDBC URI used for different Driver access varies.
2.1.3. Query data
Currently, all data analyzed by Sensors is mapped to two data tables, the events table and the users table, but is displayed when you connect to JDBC for data access`event_ros_p*`、`event_view_p*` etc. the underlying table, Query data does not need to focus on these underlying tables, using the events table and user table (users) can query all the event data and user data, but need to add annotations in SQL to execute, such as querying the events data of the default project:
SELECT user_id,distinct_id,event,time,$lib as lib FROM events WHERE `date` = CURRENT_DATE() LIMIT 10 /*SA*/;Where '/*SA*/' indicates that the current SQL is a query sent to the policy system. Similarly, if you want to see what fields the events table has, you can use:
DESC events /*SA*/;If you are not querying the default item, you need to specify the item name, for example:
SELECT id,first_id,second_id FROM users LIMIT 10 /*SA(test_project)*/;Finally, we can also have one part of the SQL use divine queries and other parts use normal Impala queries, such as:
CREATE TABLE test_data AS /*SA_BEGIN(test_project)*/ SELECT id, first_id, $city AS city FROM users LIMIT 10 /*SA_END*/;In this way, it is also easy to JOIN the divine data with other external data tables.
Special attention, If your project has many-to-one user association enabled,If the /*+remapping_on*/ comment is not added, the data is exported by default without much repair.If you need to export the data after the many-on-one repair, first ensure that your impala version is greater than or equal to 3.2.0.069 (consult the student on duty to confirm), and then add /*+remapping_on*/ comments to the query export statement, for example
SELECT * from events limit 1 /*SA(default)*/ /*+remapping_on*/;2.2. Matters needing attention
- Using JDBC for data access does not require an account or password.
- The SQL executed needs to be annotated to look up the events and users table data.
3. Q and A.
3.1. Query using impala-shell
In addition to directly using the JDBC interface, you can also directly use the impala-shell tool to query information. It is usually used in two ways:
Log in to any Oracle server and run the impala-shell command.
impala-shellCODE- Use any impala-shell client above 2.6.0 to connect to the address in the hive_url_list above (no need to specify a port).
The database name used by Sensors is rawdata. Switch to rawdata before querying or exporting data.
use rawdata;CODE
3.2. Data export
If you want to export the data from Sensors into text format for backup or other purposes, you can use the following scheme:
impala-shell -q 'CREATE TABLE export_data STORED AS parquet LOCATION "/tmp/impala/export_data" AS /*SA_BEGIN(default)*/ SELECT id, first_id FROM users LIMIT 10 /*SA_END*/;'CREATE Statement Interpretation:
- CREATE TABLE table_name: Create a text format data table named export_data (table_name can be customized)
- STORED AS parquet: Specify the storage format of the file, here it is specified as parquet format, which can also be defaulted to text format
- LOCATION "path": Need to specify the directory to /tmp/impala on HDFS or other directories with permissions. It is recommended to use the directory format /tmp/impala/table_name to distinguish different data tables.
AS SQL statement with comments: The data to be exported is after AS, and note that the annotation /*SA_BEGIN(project)*/ SQL statement /*SA_END*/ needs to be added to execute. The project should be filled in with the actual project name in English. If the English project name is unknown, you can refer to the following method:
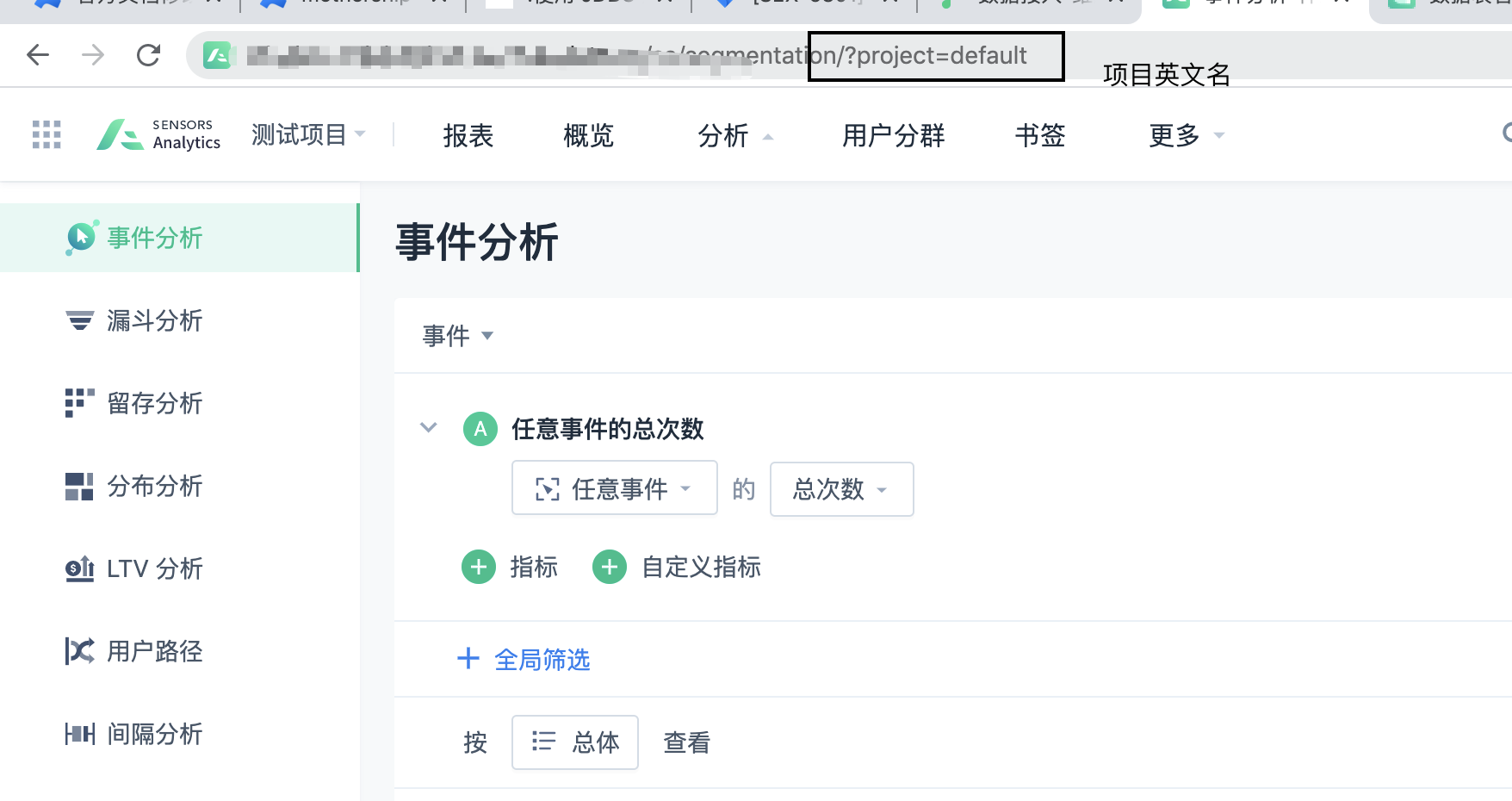
After a successful execution, the default.export_data data table is created successfully.
Note: 1. If you are prompted that you do not have the permission to create a table, please contact Sensors Operations for assistance.
2. Ordinary Impala/Hive tables do not support fields with $. Therefore, if you need to export such fields, you need to use AS to rename them.
Execute impala-shell, query the table, and get the HDFS path of the data table
SHOW TABLE STATS default.export_data;The Location column in the output is the HDFS directory where the exported file is located, for example:
hdfs://data01:8020/tmp/impala/export_data
You can use the hadoop command to retrieve the HDFS file to the local machine, which is by default in the /home/sa_cluster/ directory. For example, find the local file under the /home/sa_cluster/export_data/ path:
hadoop fs -get hdfs://data01:8020/tmp/impala/export_data- The file in the above directory is a text file with column separation using the Hive default delimiter (\001).
- Copy the files under the above path as needed.
- Delete the Sensors HDFS files to avoid occupying storage space on the Sensors server.
Note: The content of this document is a technical document that provides details on how to use the Sensors product and does not include sales terms; the specific content of enterprise procurement products and technical services shall be subject to the commercial procurement contract.
 Popular Searches
Popular Searches