標籤數據匯出
匯出概述(必讀)
神策標籤系統的數據匯出,與神策分析基本一致,可參考[ 神策分析|https://www.sensorsdata.cn/manual/data_export.html][ - |https://www.sensorsdata.cn/manual/data_export.html]數據匯出。 其中標籤最常見的匯出方式有:
# | 訪問方式 | 場景 | 用於頁面展示 | < 5k 行導出 | 5k - 10W 行導出 | > 10W 的無限制行導出 |
|---|---|---|---|---|---|---|
1 | 查詢 API(不分頁) |
| 不建議使用 | 支援 | 支援 | 不建議使用 |
2 | 查詢 API(分頁) |
| 支援 | 支援 | 不建議使用 | |
3 | JDBC(包括 impala-shell)+ HDFS |
| 不建議使用 | 支援 | 支援 | 支援 |
4 | HUE SQL 查詢 |
| 支援 | 支援 | 支援 | 不建議使用 |
使用 JDBC + HDFS 查詢或匯出分頁
本章節為參考https://www.sensorsdata.cn/manual/jdbc.html 編寫,原文中包含更多內容如 "和 Spark 集成"。
取得 JDBC 位址
登錄任意的神策伺服器
切換至 sa_cluster 帳號
su - sa_cluster
使用以下命令獲取位址
spadmin config get client -m impala
例如輸出是
{
"hive_url_list": [
"jdbc:hive2://192.168.1.2:21050/rawdata;auth=noSasl",
"jdbc:hive2://192.168.1.3:21050/rawdata;auth=noSasl",
],
"hive_user": "sa_cluster"
}
其中,hive_url_list 中的任意一個位址都可用於連接。
如果使用代碼訪問,我們建議使用 1.1.0 版本的 Hive JDBC Driver 來進行存取,Maven 的依賴定義如下:
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.1.0</version>
</dependency>
另外,Impala 也支援使用官方的Impala Jdbc Drvier進行存取,不過為了相容神策分析系統,請使用的時候務必開啟 Native SQL 的選項,例如:
jdbc:impala://192.168.1.1:21050/rawdata;UseNativeQuery=1
注意:使用不同 Driver 訪問時使用的 JDBC URI 也會有所不同。
使用 impala-shell 進行查詢
可以直接使用 impala-shell 工具進行查詢。 通常有兩種使用方式:
- 直接登錄任意的神策伺服器,運行 impala-shell 命令即可。
- 使用任意 2.6.0 以上的 impala-shell 用戶端,連接到上面 hive_url_list 中的位址(無需指定埠)。
簡單查詢及 SA 註解
為了區分查詢神策的數據與一般的 Impala 資料,需要在 SQL 中使用特殊的註解來進行標識,需要在 SQL 中使用特殊的注解來進行標識,例如查詢預設專案的 events 資料:
SELECT * FROM events WHERE `date` = CURRENT_DATE() LIMIT 10 /*SA*/;
類似的,如果想看 events 表有哪些欄位,可以使用:
DESC events /*SA*/;
如果不是查詢預設專案,則需要指定項目名稱,例如:
SELECT * FROM users LIMIT 10 /*SA(test_project)*/;在 HUE 中不加 SA 註解地驗證 SQL 正確性
在HUE (既 "自訂查詢「)中可以不加註釋地查詢神策的數據,可用於快速驗證 SQL 編寫是否正確。
在 HUE 中,還可以方便地看到 users 表、user_tag_* 表、user_group_* 表的字段結構。
驗證后,可再加適當註釋再通過 JDBC、Impala-shell 等方式執行。
更多內容,可參考 「在 HUE 中查詢標籤」 一節。
獲得標籤英文名
在 SQL 中查詢標籤,需要先取得標籤英文名字,方法如下圖: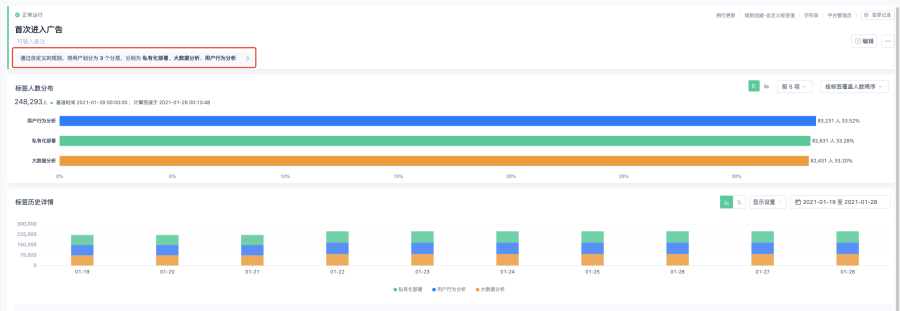
查詢標籤最新版本
假設 「年齡」 標籤,英文名是 age,查詢預設項目的標籤 age 的最新 base_time 的資料:
SELECT first_id, age FROM users WHERE age IS NOT NULL LIMIT 10 /*SA*/;
觀察 SQL 可見:
- 其中的/SA/ 表示當前 SQL 是一個發給神策系統的查詢;
- 且標籤 age 在 SQL 中,是作為 users 表的一個字段進行查詢的;
- users 表的 age 字段,是 age 標籤的最新 base_time 所代表的版本。
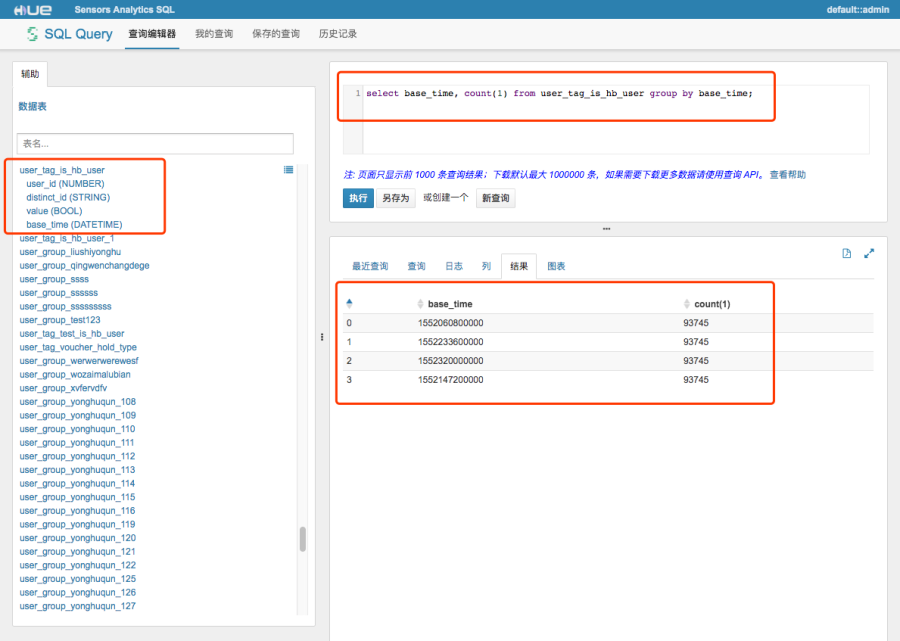
查詢標籤歷史版本
歷史版本無法從users表中查到,我們需要查詢 user_tag_(標籤)和 user_group_ (使用者群)表。
下面以 「是否為紅包使用者」 標籤為例,其英文名是 is_hb_user。
SELECT base_time, COUNT(1) FROM user_tag_is_hb_user GROUP BY base_time /*SA*/;結合 HDFS 進行資料匯出
如果想把神策的數據匯出成文本格式,用於備份或者其它用途,那可以使用以下方案:
一、創建一個文本格式的數據表,把待匯出的數據插入此表。
我們可以讓一個 SQL 的一部分使用神策的查詢,其它部分使用正常的 Impala 查詢如下:
CREATE TABLE default.age_export AS
/*SA_BEGIN(test_project)*/ SELECT id, first_id, age FROM users WHERE age IS NOT NULL LIMIT 10 /*SA_END*/
注意:普通 Impala/Hive 表不支援帶 $ 的欄位,因此如果匯出這類欄位需要使用 AS 重命名。
二、取得該資料表的 HDFS 路徑:
SHOW TABLE STATS default.age_export
其中輸出的 Location 列即是匯出檔案所在的 HDFS 目錄,例如:
hdfs://data01:8020/user/hive/warehouse/age_export/
可以使用 hadoop 命令將 HDFS 檔案取到本地:
hadoop fs -get hdfs://data01:8020/user/hive/warehouse/age_export/
上述目錄里的檔是以 Hive 預設分隔符(即 \001)進行列分隔的文字檔。
按需拷貝走上面路徑下的檔即可。
使用 API 查詢或匯出分頁
請參考https://www.sensorsdata.cn/manual/query_api.html
注意問題:可能有性能問題,不建議做大數據量的匯出,匯出大量數據最好使用 JDBC + HDFS。
匯出 JSON /user_analytics/users
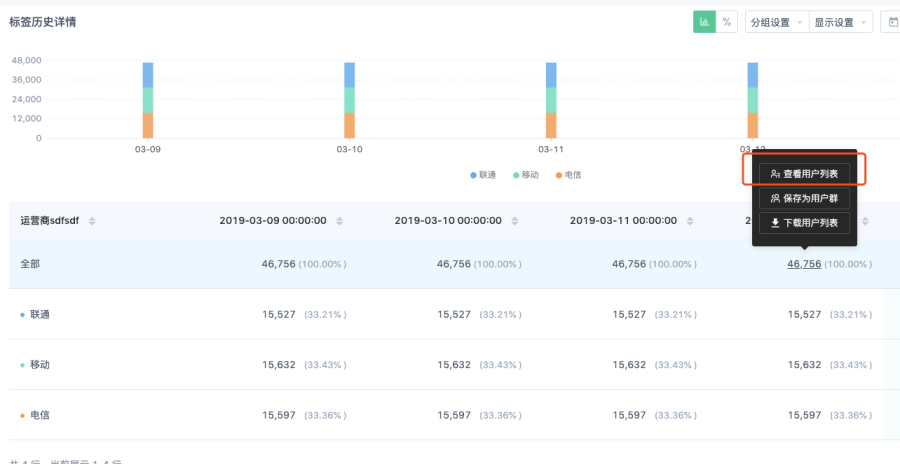
對應的 UI 操作
請求方法
- POST
PATH
- /v2/reports/user_analytics/users
Request (application/json)
{
"filter":{
"conditions":[
{
"field":"user.carrier_name",
"function":"isSet"
}
]
},
"num_per_page":50,
"page":0,
"all_page":false,
"profiles":[
"user.FirstUseTime",
"user.Mobile",
"user.age",
"user.array",
"user.bankName",
"user.carrier_name"
],
"limit":1000,
"use_cache":false
}Response
{"page_num":20,"size":1000,"column_name":["FirstUseTime","Mobile","age","array","bankName"],"permitted_properties":
["FirstUseTime","Mobile","age","array","bankName"],"users":[{"id":"-8809360118358200723","first_id":"00207d2931b40dc6","profiles":{}},
{"id":"-6760556487249273086","first_id":"004d8852b49e810f","profiles":{}},{"id":"-8822980603615477502","first_id":"006ff6de99d3234a","profiles":{}}]}欄位含義
關鍵字 | 選項 | 含義 |
|---|---|---|
by_fields | 可選 | 分組,得到的人群是按某個/某些屬性進行的分組,格式為 user.xxx |
slice_by_values | 可選 | 每個分組中的分組值,與 by_fields 同時存在 |
all_page | 可選 | 是否下載全部使用者,下載使用者清單時為 true |
profiles | 必選 | 需要顯示的列 |
detail | 可選 | 使用者清單結果中是否包括 profile 詳情 |
use_cache | 必選 | 是否使用緩存,下載使用者清單時填 false |
filter | 可選 | 過濾條件 |
field | 必填 | 標籤的屬性,格式為 user.xxx,其中 xxx 為標籤名稱 |
function | 必填 | 查詢的功能,如果想要查詢標籤中某一個值中的使用者 function 選擇 equal |
params | 可選 | 查詢的參數,如果 function 為 equal 的話,則必填。 如:「高價值」,表示篩選的用戶在標籤 xxx 中是「高價值」 的 |
page | 可選 | 分頁請求中的第幾頁 |
num_per_page | 可選 | 分頁請求中單頁多少條數據 |
匯出CSV /user_analytics/users/csv
PATH
- 與前者唯一不同是 PATH 結尾加 /csv,即 /reports/user_analytics/users/csv
Request(application/json)
- 與 /reports/user_analytics/users 相同,略.
Response
id,匿名id,註冊id,FirstUseTime,關聯設備 ID,姓名,是否刪除,註冊時間,測試運營商,渠道追蹤匹配模式,使用者 ID,省份,城市,首次廣告系列媒介,首次廣告系列來源,首次訪問時間 // 表頭
-9223174111097466405,7526b04e0463db72,,2019-02-22 05:10:14.633,,,,,,,,,,新浪,新浪,搜狐,搜狐,微信,,,,0,,電信,,-9223174111097466405,,,,,
-9196187200727468031,447c8f808ac11ae5,,2019-02-14 18:26:12.413,,,,,,,,,,微博,百度,微博,搜狐,新浪,,,,0,,電信,,-9196187200727468031,,,,,
-9192478033236701241,36c81078470f32fa,,2019-02-25 23:08:39.587,,,,,,,,,,微信,微信,新浪,搜狐,微博,,,,0,,電信,,-9192478033236701241,,,,,
-9163037612311257423,341651270f20e87f,,2019-03-01 23:02:06.315,,,,,,,,,,搜狐,新浪,百度,微信,新浪,,,,0,,電信,,-9163037612311257423,,,,,
-9137409658088515410,1a7080c84931f117,,2019-02-11 04:45:35.999,,,,,,,,,,百度,新浪,微博,搜狐,百度,,,,0,,電信,,-9137409658088515410,,,,,
-9105370563694013403,2f3afb3ce0d4ea7c,,2019-02-28 00:41:49.090,,,,,,,,,,微信,百度,百度,微博,百度,,,,0,,電信,,-9105370563694013403,,,,,
-9098029065884906907,046d3ed103e358fb,,2019-03-18 20:22:26.938,,,,,,,,,,新浪,新浪,微信,新浪,微博,,,,0,,電信,,-9098029065884906907,,,,,
-9090550161078373930,1da85bab27969438,,2019-02-14 01:43:48.570,,,,,,,,,,百度,新浪,微博,百度,搜狐,,,,0,,電信,,-9090550161078373930,,,,,
-9057722698726216012,655a95158dc1f119,,2019-02-28 05:16:44.650,,,,,,,,,,微信,微博,新浪,搜狐,新浪,,,,0,,電信,,-9057722698726216012,,,,,查詢條件舉例
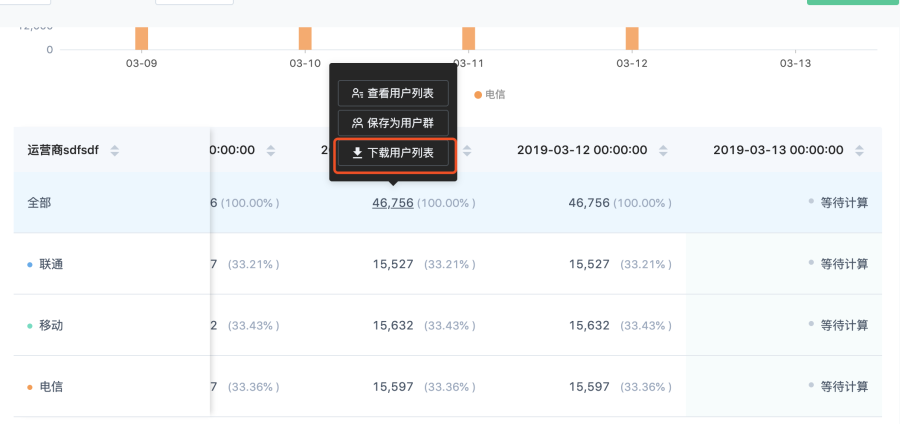
查詢歷史版本
對應的 UI 操作
Request(application/json)
{
"profiles":[
"user.carrier_name"
],
"all_page":true,
"detail":true,
"from":"user_tags",
"filter":{
"conditions":[
{
"field":"user.carrier_name@1552233600000", // @後接 partition 的 base_time 毫秒時間戳
"function":"isSet"
}
]
}
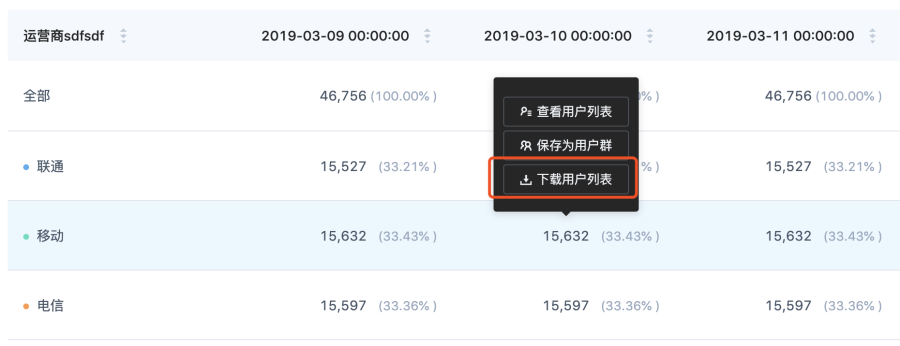
}特定候選值
對應的 UI 操作
Request(application/json)
{
"profiles":[ // 需要顯示的列,使用者屬性清單 如:
"user.FirstUseTime",
"user.referer",
"user.$utm_medium",
"user.$utm_source",
"user.$first_visit_time",
"user.carrier_name"
],
"all_page":true,
"detail":true,
"measures":[
{
"aggregator":"count",
"field":""
}
],
"from":"user_tags",
"by_fields":[ // 維度(分組)@ 後接標籤/使用者群的 base_time
"user.carrier_name@1552147200000"
],
"slice_by_values":[ // by_fields分組中的分組值,如標籤 carrier_name 分組為"移動"的結果,與 by_fields 同時存在
"移動"
]
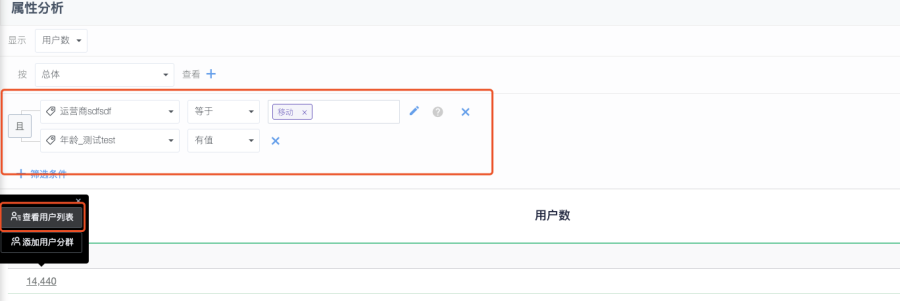
}交/並 集
對應的 UI 操作
Request(application/json)
{
"filter": {
"conditions": [
{
"field": "user.his_trd_cnts",
"function": "isSet",
"params": [
]
},{
"field":"user.carrier_name_test",
"function":"isSet",
"params": [
]
}
],
"relation": "and" // 交集為 and,聯集為 or
},
"all_page":true,
"profiles":[
"user.agentid",
"user.companygroup",
"user.companyindustry1",
"user.companyindustry2",
"user.companyname"
],
"use_cache":true
}在 HUE 中查詢標籤
在 HUE 中查詢,有兩種方式。
- 使用 user 表的欄位,這種方式查詢的是標籤的最新版本。
- 使用 user_tag_* 表,這種方式可查詢標籤的歷史版本。
使用 user 表查詢
以下面的 「年齡」 標籤為例,說下你需要知道標籤的英文名,點擊「查看規則」。 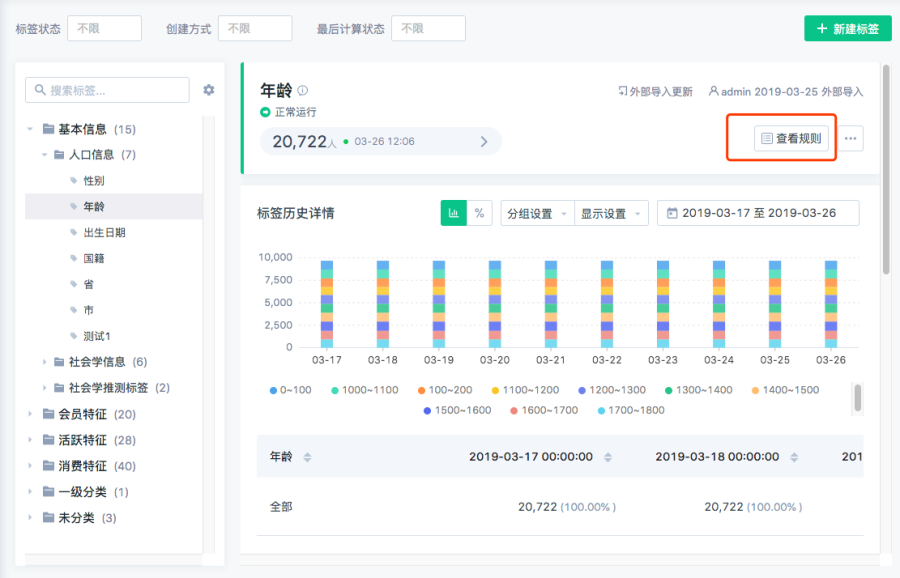
可以看到標籤英文名。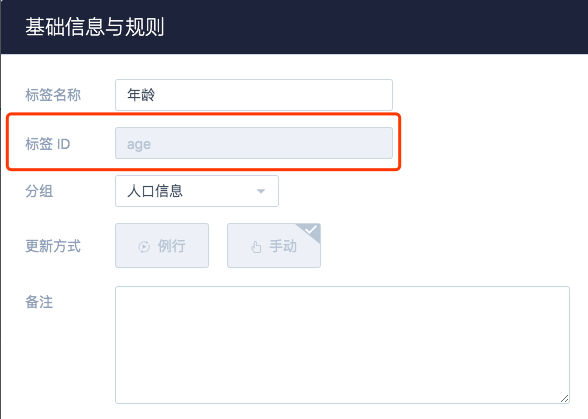
再打開 「自訂查詢」 功能。 
點開 HUE 中的 user 表,可以看到一個叫做 age 的欄位。 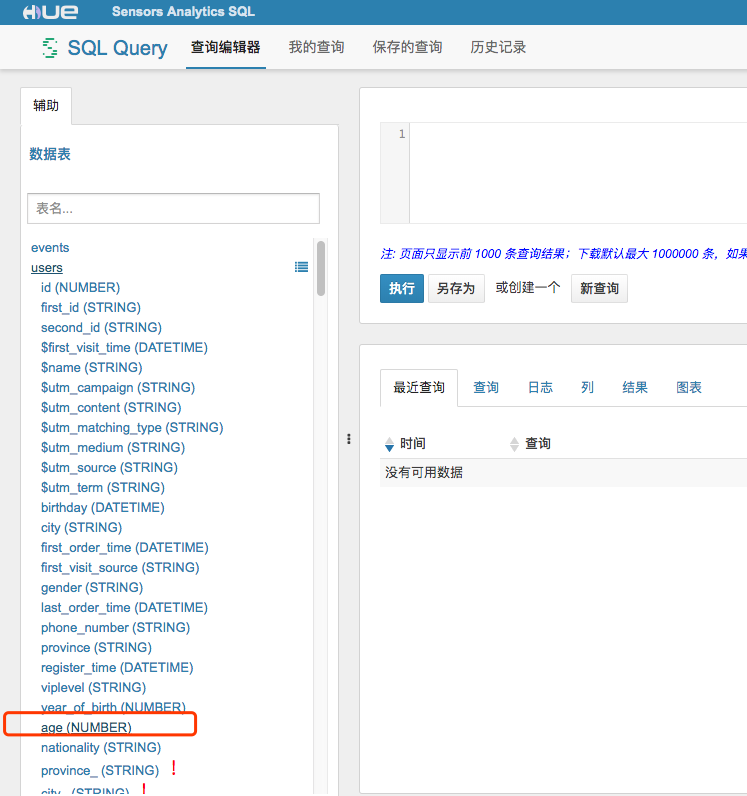
這個欄位代表的就是標籤的最新版本數據。
在 HUE 中(即神策的 "自定義查詢「 功能),可以看到 user 表存在一個對應欄位。 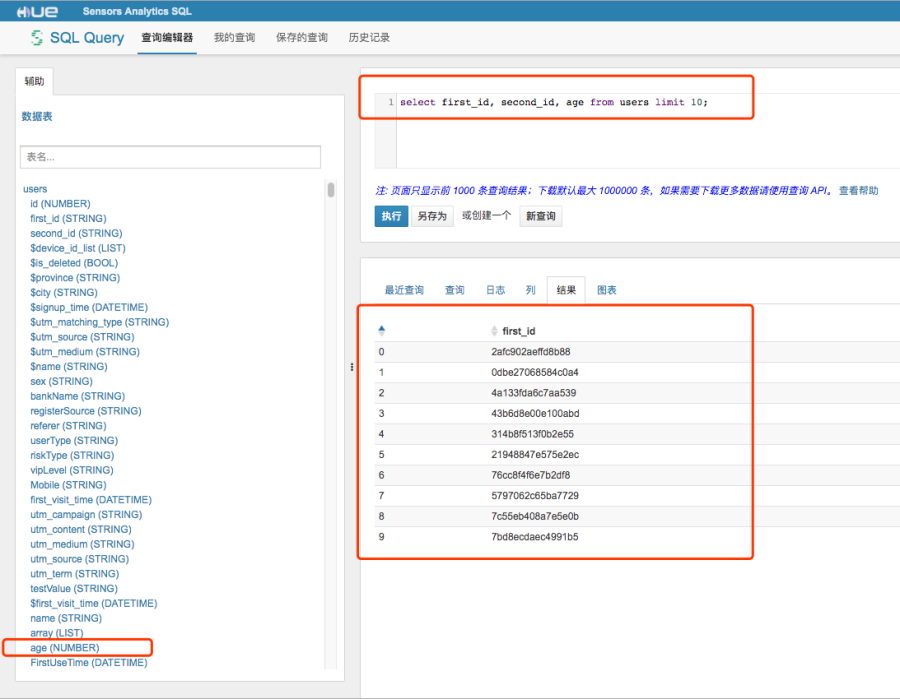
使用標籤表查詢
HUE 左側的 user_tag_* 是標籤表,user_group_* 是使用者群表,二者欄位相同。
與 users 表的最大區別,在於標籤表具有 base_time 欄位,base_time 代表了標籤版本,是毫秒的時間戳。
base_time 的產生方式:
- 例行規則標籤:通常是每天的 00:00:00,其 base_time 與相對時間的計算有關,比如 base_time 為 4-10 0:00:00,那麼 "昨天" 的含義就是 4-9 0:00:00 到 4-10 0:00:00。
- 外部匯入:匯入時參數指定。
- 單次標籤、使用者群:base_time 通常是標籤創建時間。
下圖展示了對 is_hb_user 進行 base_time 分組統計的情況。