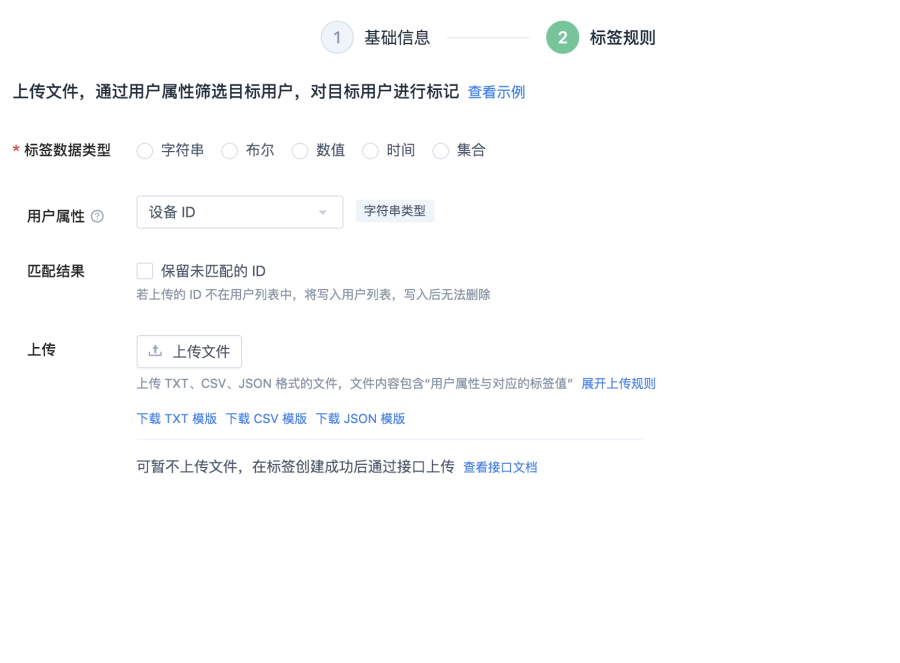
創建用戶標籤
概述
神策用戶畫像系統,提供多種使用者標籤的創建方式,您可以根據自己的標籤含義,選擇與之相對應的方式進行標籤的創建。
同時,創建標籤需要提供標籤的基礎資訊,主要包含:標籤的顯示名、標籤名稱、標籤的分組、更新方式和備註等
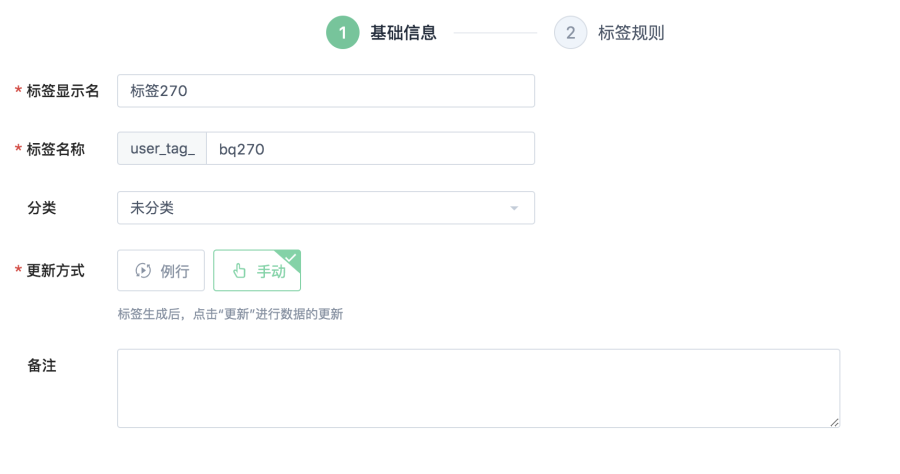
創建用戶標籤
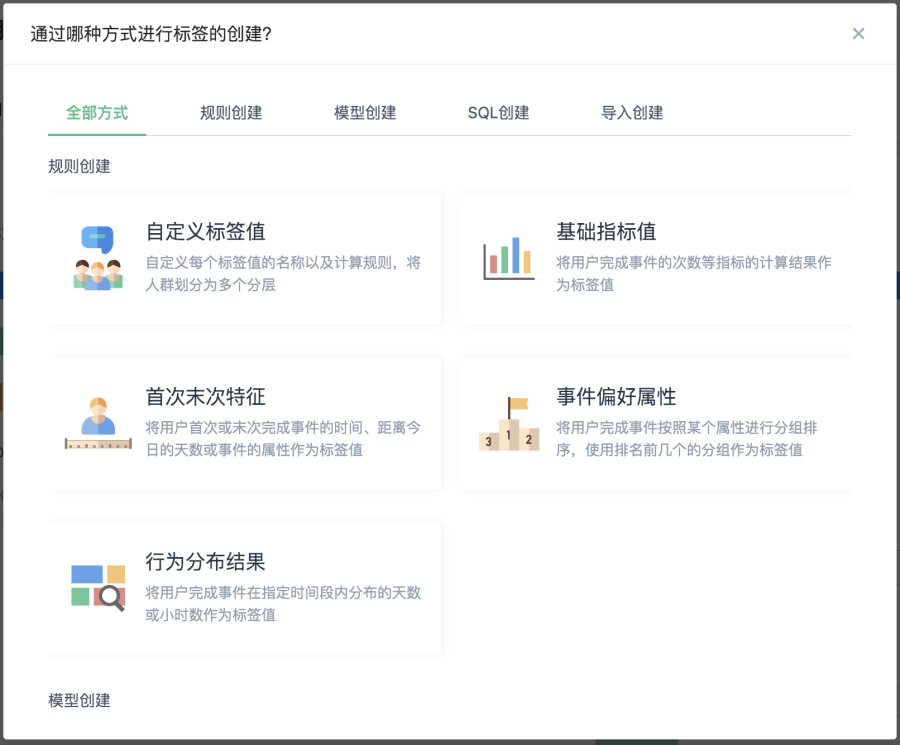
點擊「新建標籤」,展示標籤創建彈層,可根據自身使用標籤內容,選擇相應的標籤創建方式。
自訂標籤值
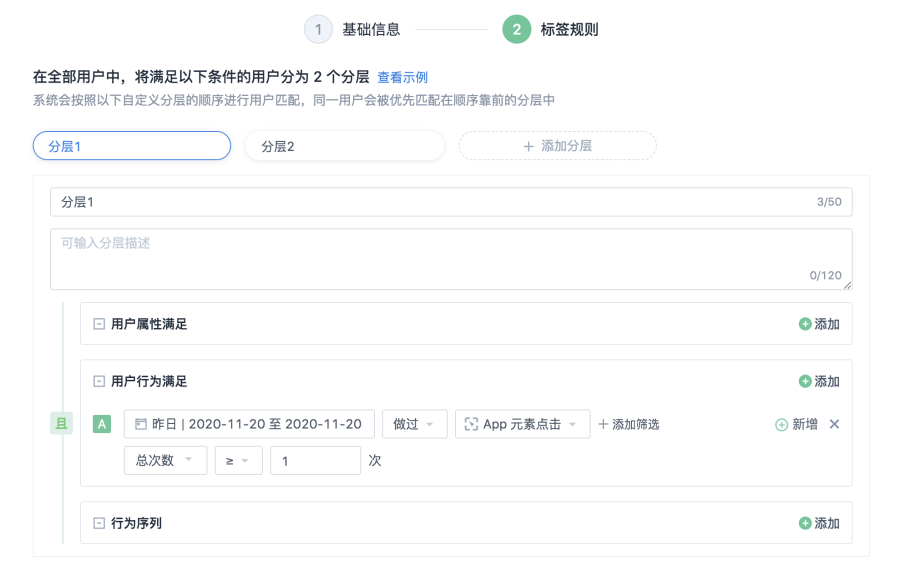
自定義標籤值中,你可以給每個標籤值進行命名,我們支援最多 24 個標籤值。 其中,你可以為每個標籤值設定其計算規則。
支援你對每一個標籤值輸入一個備註,進行內容的概括描述。
支援以下條件作為標籤值的計算規則:
用戶屬性滿足
- 使用者屬性進行過濾
- 使用者分群進行過濾
- 用戶標籤進行過濾
用戶行為滿足
- 使用者完成指定事件的總次數
- 總次數等於、大於、小於...
- 總次數為 Top 10% ...
- 使用者完成指定事件的天數分佈
- 使用者完成指定的事件的數值屬性指標
- 使用者未做過某事件
行為序列
- 用戶在時間範圍內依次完成了多個事件
基礎指標值
基礎指標值,使用使用者的行為統計結果作為標籤的值,為每個用戶進行標記。
支援計算的統計結果為:
某個指定事件的
- 完成總次數
- 屬性去重數
- 數值類型屬性的均值、最大值、最小值

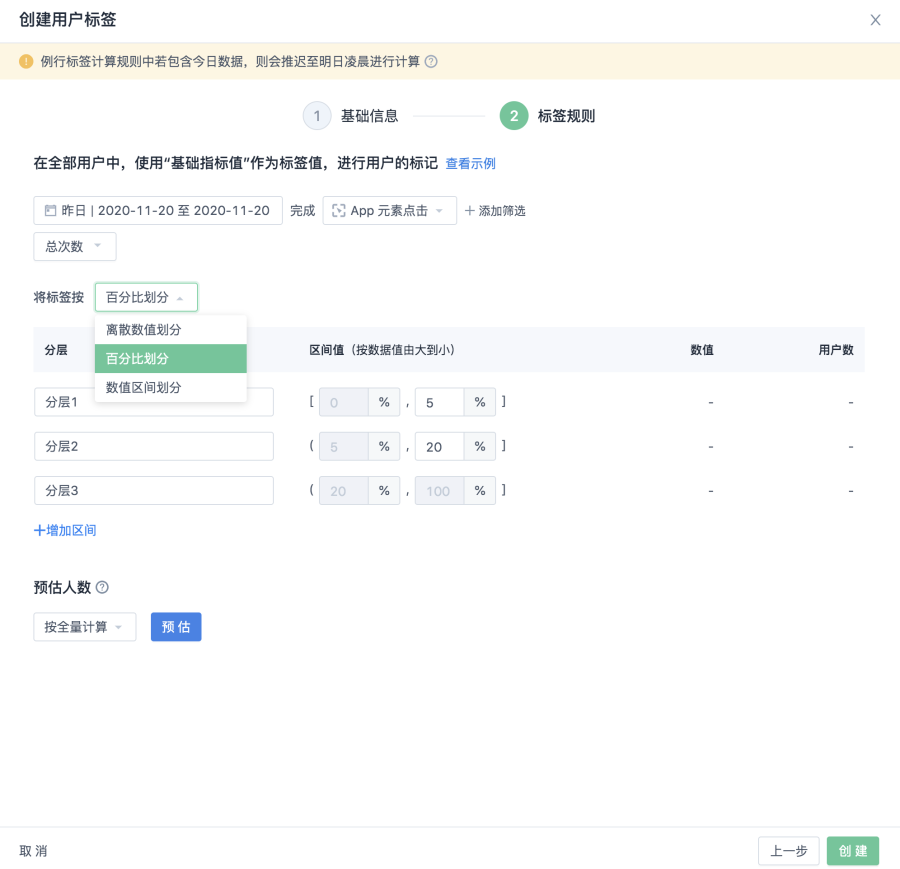
支持通過選擇基礎指標的不同劃分方式,進行分層標籤建設:
- 按百分比劃分:基於目標用戶的人數比例設置使用者分層標籤,預設按照指標值由大到小排列;
- 按數值區間劃分:基於指標值的閾值區間範圍設置使用者分層標籤;
- 按離散數值劃分:直接使用指標計算結果值作為標籤值(當標籤值為離散數值時,使用該標籤進行使用者篩選及交叉分析,性能會有所下降,建議按照百分比或數值區間進行劃分)。
抽樣設置:通過隨機抽取數據樣本方式,快速進行使用者分佈人數的預估,提升當前預估人數的計算效率。
- 注:「抽樣設置」為提升數據量過大時「預估人數」的計算效率。 點擊「建立」後,標籤按照 100% 使用者進行計算
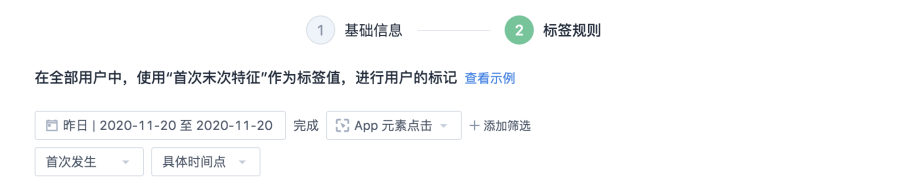
首次末次特徵
首次末次特徵,使用某個指定事件的第一次或最後一次發生的屬性特徵作為標籤的值,為每個用戶進行標記。
支援計算的特徵為:
某個指定事件的
- 首次/末次發生具體時間
- 第一次發生距離目前的日期的天數
- 首次/末次發生的事件,對應的事件屬性
事件偏好屬性
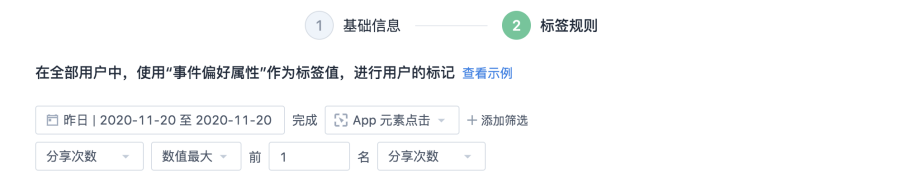
事件偏好屬性,將使用者指定事件按照某個屬性進行分組排序(如:支付訂單按照商品類型排序),將前幾名作為用戶標籤的值,為每個使用者進行標記
支援計算的特徵為:
某個指定事件的
- 出現次數最多的前幾名的某個屬性
- 某個數值屬性數值最大的前幾名,對應的事件屬性
行為分佈結果
行為分佈結果,將使用者完成指定事件的天數分佈結果作為標籤值,為每個用戶進行標記
支援計算的特徵為:
某個指定事件的
- 發生的天數分佈

相似度標籤
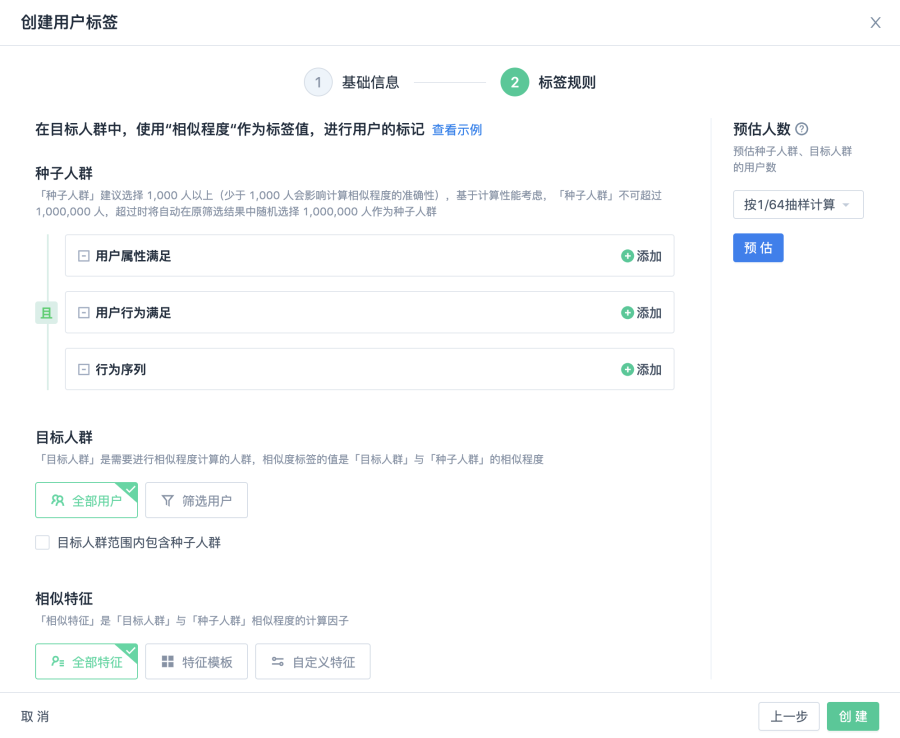
相似度標籤,運用智能演算法,將目標人群相較種子人群相似程度的計算結果作為標籤的值,為目標人群中的每個用戶進行標記。
- 種子人群是相似程度計算的基準,支援通過使用者屬性、使用者行為、行為序列進行自定義篩選。 假定通過篩選規則將種子人群定義為「高價值使用者」,則生產的標籤可以用來標記目標人群和「高價值使用者」的相似程度。
- 目標人群是需要進行相似程度計算的人群,在創建方式上,一是支持選擇全部使用者做目標人群,二是支援通過使用者屬性、使用者行為、行為序列來自定義篩選目標人群,同時支援排除目標人群中包含的樣本人群。
- 相似特徵是目標人群與種子人群相似程度的計算因數,在特徵選擇上,支援使用全部特徵、特徵模版和自定義特徵。 選擇某個特徵範本,則可以直接使用該模版中管理員預先設置的相似特徵來計算相似度標籤。
相似度標籤是一個數值類型的標籤,標籤值越大,說明目標人群和種子人群的相似程度越高。
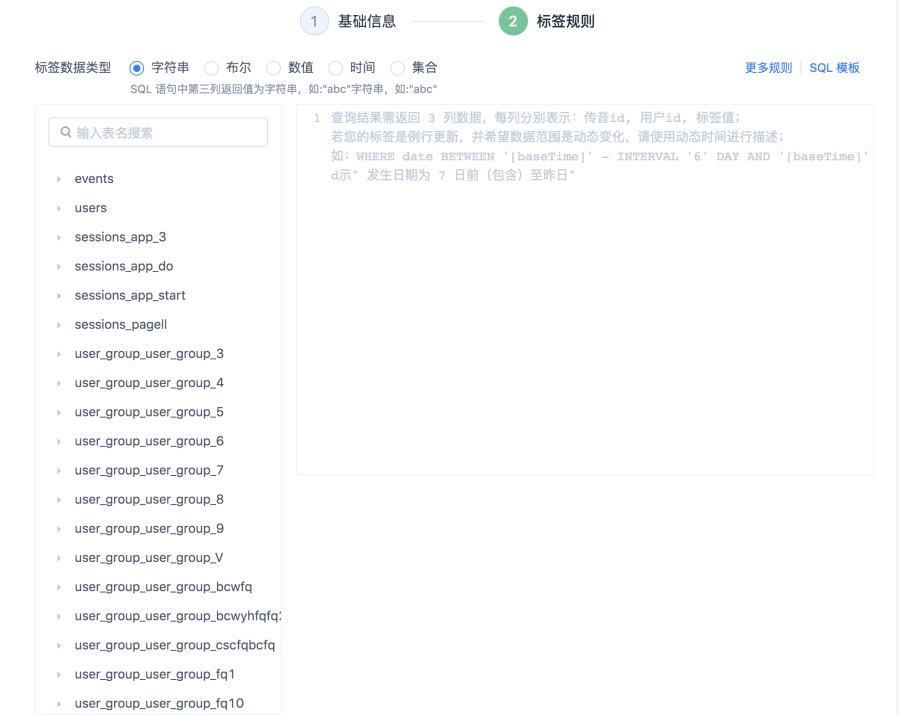
SQL 計算結果
使用 SQL 語句進行標籤的創建。 按照畫像系統中設定的規則,返回指定的 SQL 資料即可進行 SQL 標籤的創建。
SQL 標籤目前支援字串、數值、集合、時間和布爾 5 種數據類型。
匯入創建標籤
使用上傳檔計算結果作為標籤值,為用戶進行標記。 上傳包含「使用者屬性」與「屬性對應的標籤值」檔,利用上傳的使用者屬性篩選目標使用者並打標籤。
匯入標籤目前支援字串、數值、集合、時間和布爾 5 種數據類型。